SAP의 마스터 데이터가 무엇이고 SD관련 마스터 데이터 중 3가지와 관련된 내용을 살펴본다. Customer(business partenr)에 대한 내용은 나중에 제대로 다루고, Pricing도 간단하게 다루고 나중에 제대로 세세히 살펴본다.
Material Master
Customer-Material info records
Pricing condition master records
1. Material Master
SAP에서 마스터 데이터란 회사의 고객, 임직원, 공급자, 제품, 자산 등에 관한 비즈니스 데이터를 뜻한다. 트랜잭션 데이터는 기업의 활동으로 인해 발생하는 데이터를 뜻한다. 예를 들면 자재 '1001'은 마스터 데이터이지만 이 자재를 판매하는 주문정보인 Sales Order는 트랜잭션 데이터이다. 회사의 유형 자산인 건물 'A001' 마스터 데이터이지만, 해당 건물의 감가상각비를 처리한 회계전표는 트랜잭션 데이터이다.
1.1. Maintaining Material Master ( 관련 T-CODE : MM01, MM02, MM03 )
SD 모듈에서 비즈니스 트랜잭션이 처리되는 동안, 많은 데이터가 마스터 데이터에서 Sales Document로 전달된다. 이 데이터들은 다시 Delivery(Shipping), Billing 문서들로 전달되며 처리된다. 그러므로 미리 비즈니스 트랜잭션을 발생시키기 전에 정확한 마스터 데이터를 만들어 놓아야 한다. 이 마스터 데이터들은 몇몇 조직 구조 레벨(ex. Sales Org, Plant 등)에서 정의되기 때문에 정확한 값으로 마스터 데이터를 확장해 두어야 제대로 비즈니스 트랜잭션이 수행된다.
Material 을 정의하기 위해서는 먼저 Industry Sector와 Material Type을 지정해야 한다.
Industry Sector : 자재가 속하는 산업을 정함(retail, chemical, mechanical engineering), 자재의 industry sector가 자재가 가지고 있어야할 필드와 자재 정보화면(MM01,MM02,MM03)의 스크린 순서를 정한다. 즉, 어떤 view와 필드들을 가질 지 미리 정의된 템플릿을 정하는 값이다.
Material Type : 비슷한 성격으로 그룹화하기 위한 값(services, trading goods, raw materials 등). 자재 번호를 내부적으로 채번할지 외부적으로 채번할 지 정하거나, 가치 평가를 이동평균법으로 할 지, 표준원가법으로 할 지 정하는 기준이 된다. 또한, Industry Sector와 마찬가지로 스크린의 순서와 필드 여부를 결정하는 값으로 쓰인다.
Industry Sector, Material Type
DIEN - Service : Storage 데이터가 없고 생산되거나 벤더로부터 공급받을 수 없는 자재 유형이다.
FERT - Finished Product : 제품, in-house로 제조하는 상품이며 구매될 수 없는 자재 유형이다.
HAWA - Trading Goods : 벤더로부터 구매한 자재로 추후 따로 추가적인 변형을 거치지 않고 고객에게 판매하는 자재 유형이다.
KMAT - Configurable Materials : 기본 자재(Material) 코드 하나로 다양한 변형 제품을 생성가능 (Customizing 가능)
NLAG - Non-Stock Material : 무형의 자재들을 나타냄, 대표적으로 소프트웨어와 라이센스, 접근권한(구독 등)이 있음.
1.1.1 Material Master Views
Material Master는 앞서 이야기했듯, 여러 조직단위로 나뉜다. 각 단위별로 나뉜 단위별로 할당받은 데이터 집합 각각을 view라고 한다. 아래와 같이 여러 view가 있다. Basic data는 말 그대로 기본적인 정보이며 모든 부서가 공유하는 공통 데이터이다. view 이름에서 알 수 있듯 Sales views는 영업 관련 부서, Purchasing과 MRP는 구매, 자재관리 모듈, Accounting은 회계 등 각각의 부서에서 직접 마스터 데이터를 관리한다. 해당 부서의 담당자들이 각 마스터 데이터 뷰의 데이터를 정하고 유지보수한다.
Material Master views
Maintenance status : 자재가 어떤 view가 유지보수되었는지(확장되었는지) 나타내는 필드값(MARA, MARC table 등에 있다)
User department
Maintenance status
Accounting
B
Basic data
K
Classification
C
Costing
G
Forecasting
P
MRP
D
Plant stocks
X
Production resources/tools
F
Purchasing
E
Quality management
Q
Sales
V
Storage
L
Storage location stocks
Z
Warehouse management
S
Work scheduling
A
예를 들어 KVBXZ 값이 필드에 있다면 해당 자재를 각 VIEW로 확장했다는 뜻이다.
1.1.2 Basic Data 1, 2
Material (Material number) : 내부적으로(자동으로) 채번되거나 외부적으로(수기) 채번되도록 지정할 수 있다.
Descr : 자재의 이름을 나타내는 필드
Base Unit Of Measure : UoM은 재고를 관리할 때 쓰인다. 얼마나 재고가 있는 지 나타낼 때 쓰는 단위. 재고를 쓸 때 쓰는 단위를 SKU(Stock Keeping Unit)이라고도 쓴다.
Material Group : 비슷한 자재끼리 그룹화할 수 있는 필드. 앞서 조직 구조에서 Division이나 자재 생성시 설정하는 Material Type처럼 자재를 구분하는 기준이 되는 여러 필드 중 하나이다.
X-Plant Mat.Status(cross-plant material status) : 자재의 생명주기(lifecyle) 단계를 나타내고, 그 상태가 모든 plant에서 공통적으로 적용될 지 여부를 나타내는 필드값.
Prod.hierarchy(product hierarchy) : 자재계층구조, 자재를 레벨별로 나누어 분류할 수 있는 필드. 최대 9레벨까지 계층 구조를 설정할 수 있다.
3 Level 자재계층구조 예시
Division : SD모듈 조직구조에서 배운 Division을 뜻한다. Sales view가 아닌 basic data view에 있는 일반 데이터이다. Sales Organization과 Distribution Channel과 함께 사용되어 매출형태를 정하는 데 사용된다.
GenItemCatGroup : Sales 관련 트랜잭션에서 Item Category를 결정하는데 사용되는 값이다. Sales View에도 같은 이름의 필드가 있으며 Sales 트랜잭션에서는 Sales view의 값이 우선순위가 더 높다. 즉 Sales Area별로 다른 값이 적용가능하다. SAP 전반적인 모듈에서 사용되는 값은 이 값이 적용된다.
Net weight and Gross weight : 출하/운송 모듈 트랜잭션에서 주로 사용되며, 순중량(제품 자체 무게), 총중량(제품+포장 무게)이다.
Material Is Configurable : 체크되어 있으면 변형 제품 생성이 가능하다. 고객 맞춤형 제품에서 사용된다.
728x90
1.1.3 Sales: sales org 1, 2
Sales Unit : Sales Order에서 사용되는 UoM
X-distr.chain status(cross-distribution chain material status) : cross-plant material status와 비슷한 기능. 모든 distribution channel에 대한 상태값
DChain-spec-status(distribution chain-specific material status) : 특정 Dstribution Chain에만 적용
Delivering Plant : 기본으로 제안되는 Sales Order의 Delivery plant 값. Sales order 생성 시 제안되는 값이라 바꿀 수 있음
Tax data : tax category와 tax liability를 나타냄. Tax Classification은 output tax(매출세, 부가세 등) 결정 절차에 사용된다. 이 데이터는 Sales Area별 데이터가 아닌 국가별 데이터이다. MVKE 테이블이 아닌 MLAN 테이블에 그 데이터가 있다.
Min.order qty(minimum order quantity) : Sales Order 생성 시 최소 수량
Min. Dely Qty(minimum delivery quantity) : Delivery 생성 시 최소 수량
Acct Assmt Grp Mat.(account assignment group for material) : 빌링처리 동안 회계전표를 생성할 때, 이 필드를 이용해 수익 계정(revenue)이나 deduction account(공제 계정)을 결정하는 데 이용된다. 공제 계정은 리베이트, 매출할인 등의 계정을 뜻하는 듯하다.
Item Category Group : Basic Data에 있는 필드와 같은 기능을 한다. 다만 Sales 프로세스에서는 이 값이 우선순위를 가진다.
Product hierarchy : Basic data에 있는 필드와 같은 기능을 한다. 다만 Sales 프로세스에서는 이 값이 우선순위를 가진다.
1.1.4 Sales: General/Plant
Availability check : 재고 가용성 점검 방식을 정하는 기준값. MRP와도 관련이 있다.
Batch management : 모든 plant에서 배치 단위로 관리를 할 것인지 나타내는 값. 이 값이 한 번 설정되면 재고가 현재 혹은 이전 기간에 존재하는 경우 바꿀 수 없다.
Batch management(Plant) : 선택된 플랜트에서만 배치 관리를 것인지 나타내는 값. 이 값이 한 번 설정되면 재고가 현재 혹은 이전 기간에 존재하는 경우 바꿀 수 없다.
Trans. Grp(transportation group) : 운송 관련 기준값. 모든 플랜트에 적용되는 값
LoadingGrp(loading group) : Shipping condition과 deliverying plant값과 함께 사용되어 Shipping point를 정하는 데 사용된다.
SerialNoProfile(serial number profile) : 일련번호로 제품을 관리하기 위한 설정. 제품 일련번호의 체계를 지정하는 것임.
이외에 Additional data 탭에 들어가면 추가적인 기능이 더 있다. UoM의 변환 규칙을 정하거나, 여러 언어로 Description을 설정하거나 할 수 있다.
삭제를 위한 flag를 조직 단위 별로 설정할 수도 있다.
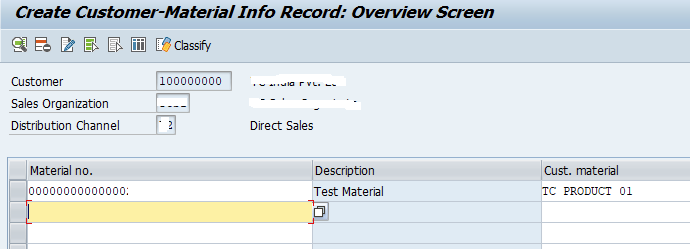
2. Customer-Material Info Records
쉽게 말하면 상대방(고객)의 Purchase Order(구매오더)의 자재코드와 자신의 SAP 시스템의 자재 코드를 매핑하는 마스터 데이터이다. 특정 Customer의 특정 Material을 자신의 SAP 시스템의 자재코드를 미리 매핑시켜놓는 마스터 데이터이다.
Sales Order 생성 시 Customer Material Number에 Cust. Material 코드를 넣으면 시스템이 매핑된 Material을 찾아온다. 판매처의 구매주문을 토대로 바로 Sales Order를 생성하는 데 쓰일 수 있다.
3. Condition Master Data for Pricing
Sales 프로세스에서 중요한 부분을 차지하는 Pricing(Price Determination), 즉 가격 결정에 사용되는 Conditon Master를 살펴본다. 한국어로는 조건으로 번역되지만 흔히 현업에서는 판(매)가, 거래조건 등으로 불린다. 여기서는 간단하게만 살펴보고 후에 자세히 학습한다.
Pricing Condition Records 형태로 시스템에 저장되어 있으며, 이 마스터 데이터들은 Sales 프로세스 중 Customer, Material, Quantity, Condition type, Org.unit 등 여러 기준을 통해 어떤 값이 채택될 지 결정되어 각 문서에 반영된다. 이런 식으로 여러 기준으로 가격 결정 절차를 수립하는 방법을 Condition Technique라고 부른다.
Pricing Condition Record를 생성할 때 Condition Type을 반드시 지정해야 한다. 이 Type 값은 해당 레코드가 나타내는 값이 gross price인지 net price인지, 혹은 discount, freight charge, tax 등 어떤 가격 결정 요소인지를 타나난다.
예시)
아래와 같은 컨디션 레코드들이 있다고 가정한다.
Condition Type
Sales Organization
Material
Value
PR00(Gross Price)
1000
XYZ
$600
위 레코드의 뜻은 Sales Org이 1000이고 Material이 XYZ일 때 합계금액은 $600라는 뜻이다.
Condition Type
Sales Organization
Customer
Material Group
Value
DC00(Customer Discount)
1000
B
M020
5%
위 레코드의 뜻은 Sales Org가 1000이고 Customer가 B이고 Material Group이 M020인 경우 5%의 할인율을 갖는다는 뜻이다.
Condition Type
Sales Organization
Customer
Material
Value
PN00(Net Price)
1000
A
XYZ
$450
위 뜻은 Sales Org가 1000이고 Customer가 A고 Material이 XYZ면 세전가격(부가세 계산 전)은 $450이라는 뜻이다.
단, PN00은 PR00보다 나중에 적용되어지는 값이다. 즉, PR00이 결정되고 PN00이 결정되면 PN00이 최종적용가격이다.
*보통 Gross Price라는 용어는 부가세 포함가격, Net Price는 부가세 제외한 가격을 뜻하지만 여기서는 부가세는 없다고 가정하고 Gross Price는 이런저런 할인 등이 적용되지 않은 최초 적용되는 기본 가격, Net Price는 최종가격으로 생각한다.
Sales and Distribution 모듈 기본 흐름 학습한다. SD 모듈에 대한 학습 전 SD 모듈에서 다루는 문서들의 흐름을 미리 암기하고 있는 것이 좋다. 이 글에서 배울 SD 모듈의 조직구조도 결국 Sales Order를 비롯한 SD 모듈의 비즈니스 프로세스에서 생성되는 문서들을 생성하기 위한 사전 세팅 값에 해당하기 때문이다.
Sales and Distribution 모듈의 Organizational Structure(조직 구조)를 학습한다. SD 모듈 조직구조 전 SAP의 Client 개념, FI모듈의 Company Code 개념 등을 배운다.
1. Sales and Distribution 모듈 기본 흐름
Sales and Distribution(SD; 영업유통) 모듈은 기업의 영업 및 제품 출하부서의 업무를 지원하는 모듈로서 사전 영업활동, 판매 주문처리, 출하관리, 대금청구 및 매출분석에 이르는 프로세스를 지원한다. 제품의 판매주문부터 현금화까지의 과정을 다룬다고 보면된다.(Order-to-Cash)
1.1 SD 모듈 문서 흐름
SD 공부를 위해 아래 5개의 문서의 흐름을 암기하고 시작하는 것이 좋다. SD 모듈은 아래 문서들을 발생시키기 위한 기능들의 집합이라고 할 수 있다.
간소화한 SD 모듈 문서 흐름
Sales Order(SD)
Sales Order(영업주문)은 영업 조직(sales organization)과 판매처(sold-to party) 사이의 재화와 서비스 제공에 대해 가격, 수량, 시간에 대한 합의를 기록한 문서.
SD 모듈의 핵심 문서로 이 문서를 만들기 위해 여러 설정값들을 사전에 세팅하고, 이 문서를 바탕으로 Delivery 및 출고, Billing(대금청구) 등의 후속 작업이 이루어진다.
관련 테이블 : VBAK(Sales Order Header), VBAP(Sales Order Item), VBKD, VBEP, VBAP
Delivery(SD, LE, TM)
Delivery(출하, 납품문서)는 재화의 운송(Shipment)과 서비스 제공 과정(피킹picking, 포장packing, 출고good issue 등)을 지시하고 모니터링하는 문서.
주로 Sales Order를 바탕으로 생성됨. 후속문서로 운송과 관련된 Shipment, Loading 등 및 자재 문서(Material Document) 등이 있다.
관련 테이블 : LIKP(Delivery Header), LIPS(Delivery Item)
Material Document(MM)
자재의 이동(입고, 출고, 재고이동, 재고 조정 등)을 나타내는 문서. SD모듈에는 주로 판매를 위한 출고를 나타내는 자재문서가 발생한다.
관련 테이블 : MKPF, MSEG
Billing(SD)
Billing(대금청구)는 출고처리가 완료된 후 Sales Order와 Delivery 데이터를 근거로 송장(invoice)를 생성하여 고객에게 대금 청구를 위해 생성하는 문서.
SD 모듈 비즈니스 트랜잭션의 마지막 단계로 Sales Order와 Delivery가 처리되면 Billing 생성이 가능해진다.
주로 Delivery가 완료되면 Delivery를 참조하여 생성하지만 서비스 매출과 같이 재화의 이동이 없어 Delivery가 없는 경우 Order를 참조하여 생성한다.
Billing 생성 시 자동으로 회계 모듈과 연계되어 Accounting Document(회계전표)가 생성되는 전기(posting)가 이뤄진다.
관련 테이블 : VBRK(Billing Header), VBRP(Billing Item)
Accounting Document(FI)
재무회계(FI) 모듈 문서. 기업 활동으로 일어나는 모든 거래는 회계 전표를 발생시킨다.
SD 모듈에서는 주로 물품의 출고로 자재문서(Material Document)와 고객에게 발생한 대금청구문서(Billing)가 전기(Posting)되어 생성되는 2가지의 회계전표가 대부분이다.
출고로 생긴 회계전표는 매출원가를 나타내는 회계전표이며 대금청구문서는 고객에게 발생한 채권을 기록하는 회계전표(AR전표라고 주로 불림)다.
관련 테이블 : BKPF(Accounting Document Header), BSEG(Accounting Document Item)
1.2 Others
위 그림은 SD 모듈을 중심으로 가장 중요한 문서들만을 나타낸 것이다.
Sales Order 전 단계로는 문의(inquiry), 견적(quotation), 계약(contract) 등의 pre-sales 과정이 있다.
Delivery 와 Material Document 사이에도 LE, TM, TD, WM, eWM 등 물류 모듈에서 Shipment, Loading 등의 과정을 다루는 문서들이 발생할 수 있다. 또한 이 과정에서 또 다른 비용이 발생하여 관련 회계전표가 생길 수 있다.
FI 모듈의 회계전표 이외에도 CO 모듈에 속하는 PA, COA 전표 등이 Delivery, Billing 과정에서 생성된다.
728x90
2. Sales and Distribution 모듈의 Organizational Structure(조직 구조)
2.1 SAP의 기본 조직 구조 - Client
Client와 Company Code
Client는 데이터베이스를 논리적으로 나누는 조직 단위
SAP의 Organizational Structure는 주로 현실에 존재하는 기업의 조직 구조를 반영한다. 예를 들면, Company Code는 현실의 법인과 1대1 대응을 이룰 수 있다. 즉, 제무제표를 발행하는 단위와 1대1 대응이 가능하다. Plant는 각 공장이나 물류센터, 혹은 사무실 등을 나타낼 수 있다. 하지만, 대부분의 SAP 책에서 조직 구조를 설명할 때 Client를 소개하는 데 이는 현실에 존재하지 않는 단위이다. 쉽게 말하면 Database를 논리적으로 나눌 때 사용하는 단위이다.
하나의 데이터베이스를 Client라는 필드(컬럼)를 이용해 나눌 수 있다. Client라는 필드가 있는 테이블들은 주로 기술적인(Technical) 데이터가 있는 테이블이 아닌 비즈니스(Business) 관련 테이블들이 대부분이다. 예시로 Sales Order 데이터가 담긴 VBAK 테이블과 프로그램 소스코드가 담긴 TADIR 테이블을 살펴보자.
VBAKTADIR
Sales Order 와 같은 비즈니스 데이터를 담는 테이블에는 MANDT라는 Client를 나타내는 필드가 잇지만 SAP 시스템의 오브젝트같은 시스템적인 데이터를 담는 TADIR 테이블에는 MANDT 필드가 없다.Client 필드는 주로 하나의 SAP 시스템에서 비즈니스 데이터를 나누는 기준이 될 수 있는 필드이다.
하지만, 실제로 운영 환경에서 client를 여러 개 만들어 하나의 SAP 시스템 내에서 비즈니스 데이터를 나누는 경우는 거의 없다. 그렇다면 왜 client 개념이 존재하는 걸까? 그 이유는 운영 환경이 아닌 개발과 품질 서버에서 사용하기 위해서다. SAP 개발 서버에서는 프로그램 개발만 작업할 수 있는 Client, IMG 세팅만을 작업하는 Client, 단위 테스트를 진행하는 Client 등으로 나누기도 한다. 또한, 품질 서버에서는 통합 테스트를 위한 client, 학습을 위한 client 등으로 나누는 등 여러 경우가 있다.
출처 https://help.sap.com/docs/
위 그림은 SAP의 공식문서에서 가져온 그림이다. 왼쪽부터 각각 개발서버, 품질서버, 운영서버에 해당하고 각 네모 칸이 Client에 해당한다. 서버 자체는 3개 뿐이지만 개발서버는 3개의 client(커스터마이징, 테스트, 샌드박스)로 나눴고, 품질은 2개의 클라이언트(품질테스트, 트레이닝)로 나눴고 운영 환경은 하나의 Client만을 사용하고 있다.
따라서, 모듈에 대한 학습을 진행할 때는 Client 밑 단계인 Company Code 부터 신경쓰면 된다. 모듈 학습은 비즈니스 데이터의 처리에 대한 학습이지 SAP 시스템 구조에 대한 학습이 아니기 때문에 Client가 있다는 정도만 알면 된다.
2.1 SAP의 기본 조직 구조 - Company Code
앞서 간단히 언급한 것처럼 Company Code는 일반적으로 현실세계의 회사와 1대1 대응된다. SAP는 재무제표를 생산하므로 회사 코드는 계정과목표(Chart of Accounts)를 가진 법적인 실체(legal entity)를 나타낸다. 기업집단(그룹사)이라면 각각의 계열사들이 Company Code를 가지게 된다. T-CODE SPRO에서 IMG 세팅을 통해 회사코드를 정의할 수 있다. 회사 코드는 FI 모듈의 최상단에 있는 조직 구조이다. 타 모듈의 조직 구조도 대부분 Company Code 하위에 속한다. 예를 들면, SD 모듈의 최상단 조직 구조인 Sales Organization도 Company Code에 하위에 속한다.
Company Code Basic Data
*IMG란 Implementation Guide의 약자로, SAP 시스템의 각종 설정들을 하는 프로그램을 의미한다. Company Code와 같은 기업을 나타내는 데이터부터 Pricing 절차와 같이 매출 발생 시 판매가를 결정하는 세세한 절차까지도 미리 설정할 수 있다.
SD 모듈의 핵심적인 기능은 주로 Sales Area를 기준으로 동작한다. Sales Area의 3가지 요소를 간단하게 설명하면, "Sales Organization은 '누가', Distribution Channel은 '어떻게', Division은 '무엇을' 파는가?"라고 할 수 있다. 즉, 3가지 구성 요소의 조합으로 매출의 유형을 나눠 각 경우마다 어떤 방식으로 매출을 처리할 지(예를 들어, 가격은 어떻게 설정할지, 세금은 어떻게 처리할지, 어떤 회계계정을 매출수익계정으로 쓸 지 등)를 결정하거나 유도한다.
2.2.1 Sales Organization(영업 조직)
재화와 서비스의 판매와 유통을 담당하는 법적 실체를 나타낸다. Sales Org.는 SD모듈의 최상단 관리 기준점이 되므로 최대한 적은 가지 수로 편성하는 것이 좋다. 그래서 여러 Sales Org를 Company Code에 할당할 수 있지만 보통은 1:1로 관리한다.
하나 이상의 plant를 Sales Org에 할당할 수 있다.(정확히는 Distribution Chain. 밑에서 설명)
주소(address)가 세팅되어야 한다. SAP에서 법적 실체를 나타내는 조직 구조 단위는 대부분 Address 정보를 가진다.
material이나 customer를 Sales Org 기준으로 구분할 수 있다. cross-Sales Org. 마스터 데이터는 불가능하다. 즉, Sales Org.별로 마스터 데이터를 확장해야 한다.(정확히는 Sales Area 별로 확장해야 한다. Division 까지 설명 후 다시 설명)
Sales Org 각각에 특정 Sales Document Type만을 허용하도록 할당할 수 있다.
모든 Sales Document의 아이템들은 하나의 Sales Org에 속한다. 즉 Sales Document의 헤더에는 항상 Sales Org가 있다.
각각의 Sales Org는 표시통화(Currency for statistics, 재무제표 작성용 통화, 반대말은 기능통화)와 고유의 달력(Calendar)를 가진다. 달력은 Delivery date 결정, ATP(Available to Promise, 재고 가용성) 점검 등에 사용된다.
여러 회사 코드를 가지는 시스템을 사용한다면, 관계사 간 거래를 위해 각 회사의 영업조직을 나타내는 Customer를 Intercompany Billing을 위해 정의해두어야 한다.
2.2.2 Distribution Channel(유통 채널)
앞서 Dist Ch.은 '어떻게'라고 설명했다. 예를 들어, Online, Wholesale(도매), Retail(소매), Direct(회사직판) 등으로 나눌 수 있다. 재화와 서비스가 팔리는 방식에 대해 정의한다. 내수/수출로 나누는 경우도 있다.
Dist Ch.은 여러 개의 Sales Org.에 할당될 수 있다. Sales Org. + Dist Ch. 조합을 'Distribution Chain'이라고 부른다.
하나 이상의 plant가 Dist Ch.에 할당될 수 있다. Sales Org.에도 하나 이상의 plant가 할당될 수 있는데, 사실 plant가 (Sales Org. + Dist ch.)에 할당되는 것이다. 이 할당 작업은 특정 Sales Org. + Dist ch. 조합을 사용할 때 허용되는 plant 목록을 할당하는 것이기 때문에 재고가 빠져나갈 plant라면 반드시 특정 Sales Org. + Dist ch. 조합에 할당해야 한다. 신규 Plant 생성 혹은 신규 Dist Ch. 생성 시 반드시 해야하는 작업 중 하나이다. 참고로 다른 회사 코드 아래에 속한 Plant도 할당할 수 있다.
위와 같이 다른 회사 코드 아래의 Plant가 Distribution Chain에 매핑된다는 것의 의미는 다른 회사의 플랜트(B101)에 있는 재화를 우리 회사(1001)가 판매한다는 뜻이 된다. 즉, '1001'이 '1002'에게서 재화를 구매한 뒤 그 재화를 고객에게 판매하는 프로세스가 이뤄지는 것이다. 그렇게 되면 '1002'입장에서는 재화를 '1001'에 판매하는 것이 된다. 이 방식의 매출이 이뤄지면 '1002'가 '1001'에 대금청구를 하게 된다. 나중에 Third Party Order에서 Vendor가 Inter Company인 경우를 배울 때 자세히 배운다.
material이나 customer를 Dist Ch. 기준으로 구분할 수 있다. 즉, Dist Ch. 별로 마스터 데이터를확장해야 한다.(정확히는 Sales Area 별로 확장해야 한다. Division 까지 설명 후 다시 설명)
Dist Ch. 각각에 특정 Sales Document 유형만을 허용하도록 할당할 수 있다.
Sales Office를 Dist Ch. 에 할당할 수 있다.(정확히는 Sales Area에 할당하는 것)
Sales 와 Billing document의 모든 아이템은 같은 Dist Ch.을 가져야 한다. 즉, Sales doc과 Billing doc의 헤더에 Dist Ch.이 있고 모든 아이템은 이 Dist Ch.에 속한다. 하지만 Delivery의 경우 아이템 레벨에 Dist Ch.가 있다(LIKS가 아닌 LIPS에 Dist Ch. 필드가 있다). 즉, 같은 Delivery 문서에 여러 Dist Ch.이 존재할 수 있다. 실제 현장을 예로 들어 설명하자면, 물류 센터에서 출하할 때는 어떤 재화가 소매로 팔리든 도매로 팔리든 정확한 목적지로 정확한 양을 보내기만 하면 되니 출하를 관리하는 Delivery 문서에서는 Dist Ch.을 기준으로 문서를 관리하지 않고 아이템 레벨에 Dist Ch.을 두는 것이라 생각하면 이해하기 편하다.
2.2.3 Division(제품군)
'무엇을'에 해당하는 Div(제품군)는 Material Master의 General(Basic) 데이터에 있다. 어떤 종류의 Material인지 나타낸다. Material Master에는 Material Group, Product Hierachy 등 Material을 구분하는 다양한 필드들이 있는 데, Division 또한 마찬가지로 Material을 나누는 기준이 되는 필드 중에 하나이다. Division은 SD 모듈 입장에서 분류하는 데 쓰인다.
예를 들면, 자동차의 전장 부품 A001(승용차용 배터리), A002(트럭용 배터리)가 있을 때, 두 Material 모두 Material Group은 '2000 : 전장 부품'으로 같은 필드 값을 갖지만, Division은 A001은 '10 : 승용차', A002는 '20 : 트럭'이라는 값을 가질 수 있다. Material Group은 자재 관점(MM), Division은 영업 관점(SD)에서 바라보기 때문에 MM 시점에서는 같은 종류이지만 영업 관점에서는 다른 종류로 판단할 수 있다.
Division은 하나 이상의 Sales Organization에 할당될 수 있다.
Division은 하나 이상의 Distribution Channel에 할당될 수있다. 즉 Sales Area의 마지막 레벨이다.
Sales Area
위 그림에서 가능한 조합의 개수는 2*3*5 = 30 이다. Sales Org는 주로 회사코드와 1대1 매핑으로 회사 당 15개의 조합을 정의할 수 있다. 즉 15개 형태의 매출 형태를 Sales Area레벨에서 정의할 수 있다는 것이다.
Sales Office는 여러 Division에 할당될 수 있다. 즉 여러 Sales Area에 할당된다.
Sales Document type을 정의할 때, 해당 문서의 모든 item들의 division이 같도록 강제할 수 있다. 즉, 생성할 문서의 Sales Area의 Division에 해당하는 material들만 해당 Sales doc에 넣을 수 있는 것이다. 이 말은 VBAK나 VBAP 두 테이블 모두에 Dvision 필드(SPART)가 있다는 뜻이 된다.
이와 반대로 Delivery나 Billing에는 서로 다른 Division 값을 가진 item들이 들어갈 수 있다. Delivery는 창고에서 물건이 나갈 때 굳이 승용차용 배터리, 트럭용 배터리를 나눠 따로따로 출고하는 것이 비논리적임을 생각하면 이해가능하고, Billing도 마찬가지로 고객에게 대금을 청구하는 것이 목적이므로 Billing 문서의 item들의 Division이 굳이 같아야할 필요는 없다. 다만, 데이터 관리 편의를 위해, Sales Order - Delivery - Billing이 모두 1:1:1 관계를 갖도록 강제하는 경우에는 Delivery, Billing에도 같은 Item만 오는 것이 가능하다. 참고로 Delivery의 헤더 테이블 LIKP에는 Division이 없고 LIPS에만 Division 필드가 있다. Billing 테이블 VBRK, VBRP에는 모두 Dvision 필드가 있다.
2.2.4 Sales Area 추가 설명
FI의 중요 요소인 Business Area를 결정하는 Rule에 Sales Area가 사용되는 경우가 잦다. 추가적인 CBO나 User Exit 등을 불필요하게 추가하지 않으려면 타 모듈과의 연결고리인 조직구조를 잘 구성해야 한다.
Business Area란 실적 보고 및 분석 등을 위한 기준이 되는 FI 조직 구조 단위 중 하나이다. SD와의 접점으로는 어떤 매출이 어떤 Business Area 값을 가질 지 Sales Area를 통해 설정할 수 있다.
SD모듈의 BA 결정 IMG 메뉴
2.2.5 Sales Office, Sales Group
Sales Office는 물리적인 위치를 기준으로 나눈 조직 단위이다. 예를 들면 서부지사, 동부지사, 해외사무소 등으로 나누어 Sales Document를 생성한, 즉 매출을 발생시킨 부서를 나타내는 조직 단위이다. Sales Area에 할당될 수 있다.
Sales Group은 Sales Employee들은 묶는 단위이다. Sales office에 할당된다.
이 2개의 조직 단위는 그 자체로 특별한 기능이 있지는 않다. 하지만 매출 발생처를 나타내는 중요한 역할을 맡을 수 있다. SD관점에서 매출 분석의 세부 기준이 될 수 있다. 이 두가지 조직 단위는 FI와의 접점이 따로 없어 Sales Office, Sales Group의 조합으로 Business Area를 결정하도록 CBO 테이블을 만들고 Sales document 생성 시 user exit에 해당 테이블에서 BA를 가져오도록 하는 경우가 종종 있다.
2.3 SD 모듈의 기본 조직 구조 - Logistics
SD의 메인 문서인 Sales Document 생성 시 입력되거나 결정되는 값이지만, 물류에 관련된 값들이라 Delivery와 그 이후의 과정에서 사용되는 값이 대부분이다. TM, LE, WM, TD 모듈 등에서 주로 사용되는 값들이다.
2.3.1 Plant
Plant는 SAP에서 자재 평가, 자재소요계획(MRP), 생산, 재고 관리, 비용 등 다양한 기능에서 핵심적인 역할을 수행하는 조직 구조 단위이다. 한국어로는 공장,설비,시설 등으로 번역되지만 그 보다는 더 넓은 의미에서 쓰인다. 예를 들어 공장, 물류센터, 본사 건물, 각 직영 판매장 등이 있다.
Address, Language, Country 정보를 가진다.
하나의 회사 코드에만 매핑될 수 있다.
여러 storage location을 가질 수 있다.
여러 개의 shipping point를 가질 수 있다. 즉, Shipping point를 결정하는 데 사용된다.
여러 Distribution Chain에 매핑될 수 있다.
Sales Order 생성 시 Deliverying plant(출고되는 plant)를 뜻한다.
재고 가용성 점검(ATP)에도 사용된다. 출고되는 plant를 뜻하므로 당연히 가용한 재고를 검사 수행의 단위가 된다.
Material Master 데이터의 몇몇 view는 plant 레벨에서 생성된다.
2.3.2 Storage Location
Storage Location은 자재관리(MM)의 조직 단위로 여겨지며 항상 plant에 대해서 생성된다. 즉 plant 하위 조직 구조이다.
여러 개의 storage location이 하나의 plant에 매핑된다.
Material Master 데이터의 몇몇 view는 storage location 레벨에서 생성된다.
하나 이상의 storage location이 같은 warehouse number의 매핑될 수 있다.
재고 실사(physical inventory)를 Storage Location 레벨에서 수행할 수 있다.
재고 평가(valuation)은 Storage Location 레벨에서 이루어질 수 없다. Plant 레벨에서 이루어진다.
2.3.3 Warehouse Number
WM 모듈 영역에서 사용된다. 재고 이동, 피킹, 패킹, 재고 최적화를 위한 조직 단위이다. Storage Location은 재고 저장을 위한 단위이다. 즉 WM 영역에서 사용하기 위한 조직 단위. 여러 Storage Location을 하나의 Warehouse에 매핑할 수 있다. 즉, Warehouse Number는 plant와 stroage location의 조합과 연결되는 개념이다.
2.3.4 Shipping Point
Delivery Document를 생성하기 위해 요구되는 조직 단위이다. 이 조직 단위가 고객에게 가는 배송을 관리하는 기준이 되기 때문이다. 각각의 Delivery는 하나의 Shipping point에 의해 처리된다.
Shipping Point는 여러 plant에 매핑될 수 있다.
Shipping(운송,배송)에 있어서 Shipping의 최상단 조직 구조이다.
Delivery 문서의 모든 item은 같은 Shipping point를 갖는다.
Sales Document에서는 item 레벨의 plant, loading group, shipping condition을 기반으로 결정된다.
복습문제
SD모듈 문서 흐름 (Material Document를 제외한 4개 문서 흐름) 작성하기.
Sales Order(영업주문)은 ________과 _______ 사이의 재화와 서비스 제공에 대해 가격, 수량, 시간에 대한 합의를 기록한 문서.
Billing(대금청구)는 출고처리가 완료된 후 Sales Order와 Delivery 데이터를 근거로 송장(invoice)를 생성하여 고객에게 _______를 위해 생성하는 문서.
_____는 Database를 논리적으로 나눌 때 사용하는 단위이다.
Sales Area = _______ + _______ + _______
Sales Area의 3가지 요소를 간단하게 설명하면, "Sales Organization은 '___', Distribution Channel은 ' ___ ', Division은 ' ___ ' 파는가?"라고 할 수 있다.
__________는 SD모듈의 최상단 관리 기준점이 되므로 최대한 적은 가지 수로 편성하는 것이 좋다. 그래서 여러 Sales Org를 Company Code에 할당할 수 있지만 보통은 _____ 로 관리한다.
material이나 customer를 Sales Org 기준으로 구분할 수 있다. _____ -Sales Org. 마스터 데이터는 불가능하다. 즉, Sales Org.별로 마스터 데이터를 _____해야 한다.
Sales Org. + Dist Ch. 조합을 '___________'이라고 부른다.
다른 회사 코드 아래의 Plant를 자신의 Distribution Chain에 매핑가능하다 ( O / X )
'무엇을'에 해당하는 Div(제품군)는 _________의 General(Basic) 데이터에 있다.
FI의 중요 요소인 _______를 결정하는 Rule에 Sales Area가 사용되는 경우가 잦다.
Sales Office와 Sales Group은 ______를 나타내는 중요한 역할을 맡을 수 있다.
Plant는 하나의 회사 코드에만 매핑될 수 있다. ( O / X )
Sales Order 생성 시 ______ plant(출고되는 plant)를 뜻한다.
______는 Delivery Document를 생성하기 위해 요구되는 조직 단위이다. Shipping(운송,배송)에 있어서 Shipping의 최상단 조직 구조이다.
정답 및 해설
Sales Order - Delivery - Billing - Accounting Document. Accounting Document는 회계모듈 영역이지만 매출과 관련된 전표는 사실상 SD모듈에서 대부분의 내용이 정해지므로 SD모듈영역이라고 볼 수 있다.
Sales Organization, Sold-to-Party
대금청구. 하지만 한국에서는 세금계산서가 대금청구 기능을 하는 경우가 많으므로 실제 기업의 활동에 있어서 대금청구 역할을 하는 것은 Billing 문서가 아닌 세금계산서이다. SAP내에서 한국 세금계산서 관련 기능이 따로 없으므로 주로 회계 문서와 연결점을 만든 CBO 오브젝트(테이블 등)를 생성하여 세금계산서 데이터를 관리한다.
Client
Sales Organization(영업 조직)+ Distribution Channel(유통채널) + Division(제품군)
누가, 어떻게, 무엇을
Sales Organization, 1:1
cross, 확장(extend). SAP에서 데이터를 확장(extend)한다고 했을 때는 주로 General 정보만 있는 마스터 데이터를 모듈 고유의 데이터를 가지도록 확장한다는 뜻이다. 예를 들어 Material '1004002'의 Sales View를 확장한다는 말은 특정 Sales Area에 대해서 고유한 영업 관련 데이터를 가지도록 추가한다는 것이다.
General_Purpose.dbc : database options, storage attributes, init.ora 설정값이나 파라미터를 참고할 수 있는 기본 템플릿 파일
728x90
3. 데이터베이스 실행 및 사용자, 테이블 생성, 데이터 생성
리스너 실행
netca # (Network Configuration Assistant)는 Oracle Listener를 설정하는 유틸리티
lsnrctl start # 리스너 start
lsnrctl status # 리스너 상태 확인
-- sqlplus / as sysdba 로 sqlplus 접속 후SELECT NAME, OPEN_MODE FROM V$DATABASE; -- 로 실행중인 DATABASE 확인CREATEUSER C##ERP IDENTIFIED BY1234DEFAULT TABLESPACE USERS;
GRANTCONNECT, RESOURCE TO C##ERP;
ALTERUSER C##ERP QUOTA UNLIMITED ON USERS;
오라클 12c부터는 공통계정앞에 c##을 붙이도록 네이밍 규칙이 바뀜. C## 가 붙는 이유는 12c 버전부터 등장하는 CDB, PDB 개념 때문
nano 로 테이블, 데이터생성을 위한 SQL 스크립트 파일 생성 (글 맨 아래 해당 스크립트 파일별로 적어놓음)
sqlplus를 해당 폴더에서 실행 후 @파일명 으로 스크립트 실행
EXEC DBMS_STATS.GATHER_SCHEMA_STATS('C##ERP'); -- 해당 유저의 테이블 통계 업데이트-- 생성된 테이블 row 수 확인SELECT table_name, num_rows FROM user_tables WHERE num_rows ISNOTNULL;
SQL이 참조하는 컬럼을 인덱스가 모두 포함하는 경우가 아니면, 인덱스를 스캔한 후에 반드시 테이블을 엑세스한다. ________________라고 표시된 부분이 여기에 해당한다.
인덱스 ROWID 는 ____ 주소보다 ____ 주소에 가깝다. 물리적으로 직접 연결되지 않고 테이블 레코드를 찾아가기 위한 논리적 주소 정보를 담고 있기 때문이다.
프로그래밍 언어에서 포인터는 메모리 주소값을 담는 변수를 말한다. 물리적으로 직접 연결된 구조나 다름없다. 메모리 상에서의 위치 정보인 포인터를 생각하며 인덱스 ROWID를 물리적 주소로 이해했다면 잘못 이해한 것이다. 인덱스 ROWID는 포인터가 아니다. 인덱스는 ROWID는 ____ 주소다. 디스크 상에서 테이블 레코드를 찾아가기 위한 위치 정보를 담는다. 포인터가 아니며, 테이블 레코드와 물리적으로 직접 연결된 구조는 더더욱 아니다.
메인 메모리 DB(MMDB)는 데이터를 모두 메모리에 로드해 놓고 메모리를 통해서만 I/O를 수행하는 DB라고 할 수 있다.
잘 튜닝된 OLTP성 데이터베이스 시스템이라면 버퍼캐시 히트율이 99% 이상이지만 그래도 MMDB만큼 빠르지는 않다. MMDB의 경우 인스턴스 가동 시 디스크에 저장된 데이터를 ____로 로딩하고 이어서 인덱스를 생성한다. 이 때 인덱스는 디스크 상의 주소가 아닌 ____상의 주소정보, 즉 ____를 갖는다. 따라서 인덱스를 경유해 테이블을 엑세스하는 비용이 오라클에 비해 현저히 낮다.
오라클은 테이블 블록이 수시로 에서 밀려났다가 캐싱되며, 그때마다 다른 공간에 캐싱되기 때문에 인덱스에서 포인터로 직접 연결할 수 없는 구조다. 메모리 주소 정보()가 아닌 디스크 주소 정보(__)를 이용해 ____ 알고리즘으로 버퍼 블록을 찾아간다.
읽고자 하는 ____를 ____ 함수에 입력해서 해시 체인을 찾고 거기서 ____ 헤더를 찾는다. 거기서 얻은 포인터로 버퍼 블록을 찾아간다.
인덱스로 테이블 블록을 엑세스할 때는 리프 블록에서 얻은 ROWID를 분해해서 DBA 정보를 얻고, 테이블을 Full Scan할 때는 ____________을 통해 읽을 블록들의 DBA 정보를 얻는다.
모든 데이터가 캐싱돼 있더라도 테이블 레코드를 찾기 위해 매번 ____ 해싱과 ____ 획득 과정을 반복해야 한다. 동시 엑세스가 심할 때는 ________와 ____ Lock에 대한 경합까지 발생한다. 이처럼 인덱스 ROWID를 이용한 테이블 엑세스는 생각보다 고비용 구조이다.
____는 특정 컬럼을 기준으로 같은 값을 갖는 데이터가 서로 모여있는 정도를 의미한다. CF가 좋은 컬럼에 생성한 인덱스는 검색 효율이 매우 좋다. 즉, 테이블 엑세스량에 비해 블록 I/O가 적게 발생한다.
인덱스 ROWID로 테이블을 엑세스할 때, 오라클은 래치 획득과 해시 체인 스캔 과정을 거쳐 어렵게 찾아간 테이블 블록에 대한 포인터(메모리 주소값)를 바로 해제하지 않고 일단 유지한다. 이를 '____' 이라고 한다. 이 상태에서 다음 인덱스 레코드를 읽었는데, 마침 직전과 같은 테이블 블록을 가리킨다. 그러면 래치 획득과 해시 체인 스캔 과정을 생략하고 바로 테이블 블록을 읽을 수 있다. 논리적인 블록 I/O 과정을 생략할 수 있는 것이다.
인덱스 ROWID를 이용한 테이블 엑세스는 생각보다 고비용 구조다. 따라서 읽어야 할 데이터가 일정량을 넘는 순간, 테이블 전체를 스캔하는 것보다 오히려 느려진다.
추출 건수가 늘면서 인덱스 스캔량이 느는 데서도 영향을 받지만, 테이블 랜덤 엑세스가 미치는 영향에 비교할 바가 아니다.
인덱스를 이용한 테이블엑세스가 Table Full Scan보다 더 느려지게 만드는 핵심 요인 두가지는 다음과 같다.
Table Full Scan은 ____ 엑세스인 반면, 인덱스 ROWID를 이용한 테이블 엑세스는 ____ 엑세스 방식이다.
Table Full Scan은 ____ I/O인 반면, 인덱스 ROWID를 이용한 테이블 엑세스는 ____ I/O 방식이다.
인덱스 사용 시 손익분기점 개념은 온라인 트랜잭션을 처리하는 프로그램과 DW/OLAP/배치 프로그램 튜닝의 특징을 구분 짓는 핵심 개념이다.
온라인 프로그램은 보통 ____ 데이터를 읽고 갱신하므로 인덱스를 효과적으로 활용하는 것이 무엇보다 중요하다. 조인도 대부분 ____ 방식을 이용한다. NL조인은 인덱스를 이용하는 조인 방식이다.
대량 데이터를 읽고 갱신하는 배치(batch) 프로그램은 항상 ____ 처리 기준으로 튜닝해야 한다. 대량 데이터를 빠르게 처리하려면, 인덱스와 NL 조인보다 ____ 과 ____ 조인이 유리하다.
대량 배치 프로그램에선 인덱스보다 Full Scan이 효과적이지만, 초대용량 테이블을 Full Scan 하면 상당히 오래 기다려야 하고 시스템에 주는 부담도 적지 않다. 따라서 배치 프로그램에서는 ____ 활용 전략이 매우 중요한 튜닝 요소이고, ____ 처리까지 더할 수 있으면 금상첨화다.
관리적 측면을 배제하고 성능 측면에서만 보면 테이블을 ____ 하는 이유는 결국 Full Scan을 빠르게 처리하기 위해서다. 모든 성능 문제를 인덱스로 해결하려 해선 안 된다. 큰 테이블에서 아주 적은 일부 데이터를 빨리 찾고자 할 때 주로 사용한다.
테이블 엑세스 단계 필터 조건에 의해 버려지는 레코드가 많을 때, 기존 인덱스에 WHERE절에 있는 컬럼을 추가하는 것만으로 큰 효과를 얻을 수 있다. 인덱스 스캔량은 줄지 않지만, 테이블 랜덤 엑세스 회수를 줄일 수 있다.
인덱스만 읽어서 처리하는 쿼리를 ____ 쿼리하고 부르며 그 쿼리에 사용한 인덱스를 ____ 인덱스라고 부른다.
SQL Server 2005 버전에 추가된 ____ 인덱스 기능이 있다. 인덱스 키 외에 미리 저장한 컬럼을 리프 레벨에 함께 저장하는 기능이다. 인덱스를 생성할 때 include (col) 옵션을 추가해주면 된다. 테이블 랜덤 엑세스 횟수를 줄이는 용도로만 사용한다.
____ 는 테이블을 인덱스 구조로 생성한 것이다. MS-SQL Server는 Clustered Index라고 부른다.
일반 테이블은 ____ 구조 테이블이며 대개 생략하지만 테이블 생성 시 organization heap 옵션을 명시할 수도 있다. 반면, IOT는 ____ 구조 테이블이므로 정렬 상태를 유지하며 데이터를 입력한다. IOT는 인위적으로 ____ 를 좋게 만드는 방법 중 하나다.
예를 들어, 어떤 회사에 영업사원이 100명이라고 가정하자. 영원사업들의 일별 실적을 집계하는 테이블이 있는데 한 블록에 100개 레코드가 담긴다. 그러면 매일 한 블록씩 1년이면 365개 블록이 생긴다. 사번+일자로 SUM을 수행하는 쿼리가 자주 수행된다고 했을 때 사번 기준의 클러스터링 팩터가 안 좋으므로 조회건 수 만큼 블록 I/O가 발생하게 된다. 이 때 사번이 첫 번째 정렬 기준이 되도록 IOT를 구성해주면 적은 블록만 읽고 처리할 수 있다. oraganization index 옵션을 사용하여 테이블을 생성하면 된다.
____ 테이블에는 ____ 클러스터와 ____ 클러스터 두 가지가 있다.
____ 클러스터 테이블은 클러스터 키 값이 같은 레코드를 한 블록에 모아서 저장하는 구조다.
여러 테이블 레코드를 같은 블록에 저장할 수도 있는데, 이를 '____ 클러스터'라고 부른다. 클러스터에 테이블을 담기 전에 클러스터 ____ 를 반드시 정의해야 한다. 클러스터 인덱스는 데이터 검색 용도로 사용할 뿐만 아니라 데이터가 저장될 위치를 찾을 때도 사용하기 때문이다.
일반 테이블에 생성한 인덱스 레코드는 테이블 레코드와 ____ 대응 관계를 갖지만, 클러스터 인덱스는 테이블 레코드와 ____ 관계를 갖는다. 따라서 클러스터 인덱스의 키값은 항상 Unique하다.(=중복값이 없다.)
클러스터에 도달해서는 ____ 방식으로 스캔하기 때문에 넓은 범위를 읽더라도 비효율이 없다는 게 핵심원리다.
____ 클러스터는 인덱스를 사용하지 않고 해시 알고리즘을 사용해 클러스터를 찾아간다는 점만 다르다.
3.2 부분범위 처리 활용
DBMS가 클라이언트에게 데이터를 전송할 때 일정량씩 나누어 전송한다. 전체 결과집합 중 아직 전송하지 않은 분량이 많이 남아있어도 서버 프로세스는 클라이언트로부터 추가 ____ 을 받기 전까지 그대로 멈춰 서서 기다린다.
DBMS가 데이터를 모두 읽어 한 번에 전송하지 않고 먼저 읽는 데이터부터 일정량(____ )을 전송하고 멈추기 때문이다. 데이터를 전송하고 나면 서버 프로세스는 CPU를 OS에 반환하고 대기 큐에서 잠을 잔다. 다음 Fetch Call을 받으면 대기 큐에서 나와 그다음 데이터부터 일정량을 읽어서 전송하고 또다시 잠을 잔다. 이처럼 전체 쿼리 결과집합을 쉼 없이 연속적으로 전송하지 않고 사용자로부터 ____ 이 있을 때마다 일정량씩 나누어 전송하는 것을 이른바 '____'라고 한다. 데이터를 전송하는 단위인 ____는 클라이언트 프로그램에서 설정한다. JAVA에서는 기본적값이 10이며, Statement 객체 setFetchSize 메소드를 통해 설정을 변경할 수 있다.
rs.next() 호출 시 Fetch Call을 통해 전송받은 데이터 10건을 클라이언트 캐시에 저장하고 이후 캐시에 저장한 데이터를 모두 소진한 후 rs.next()가 호출되면 추가 Fetch Call을 통해 10건을 전송받는다. 따라서 rs.next() 사이에 있는 JAVA 프로그램 로직이 오래 걸릴 이유는 없다.
order by가 있고 해당 컬럼이 선두인 index가 없으면 정렬을 마치고서야 클라이언트에게 데이터 전송을 시작한다. 즉 ____ 처리다. 정렬 컬럼이 선두인 index가 있으면 부분범위 처리가 가능하다. 인덱스는 항상 정렬된 상태를 유지하므로 전체 데이터를 정렬하지 않고도 정렬된 상태의 결과집합을 바로 전송할 수 있기 때문이다.
대량 데이터를 파일로 내려받는다면 어차피 데이터를 모두 전송해야 하므로 가급적 Array Size를 크게 설정해야한다. 그러면 Fetch Call을 줄일 수 있다. 앞쪽 일부 데이터만 Fetch하다가 멈추는 프로그램이라면 Array Size를 작게 설정하는 것이 유리하다.
Fetch Call의 특성을 이용해 중간에 멈췄다가 사용자의 추가 요청이 있을 때마다 데이터를 가져오도록 구현하고 안 하고는 클라이언트 프로그램을 개발하는 개발자의 몫이다.
OLTP 시스템은 말 그대로 온라인 트랜잭션을 처리하는 시스템을 말한다., 온라인 트랜잭션은 일반적으로 소량 데이터를 읽고 갱신한다.
OLTP 시스템이 수천수만 건을 조회하는 경우도 있다. 이 때 부분범위처리로 성능 개선을 할 수 있다. 문제는 앞쪽 일부만 출력하고 멈출 수 잇는가이다. 토드나 오렌지같은 쿼리 툴은 이미 그렇게 구현돼 있다. 이들처럼 클라이언트 프로그램이 DB 서버에 직접 접속하는 2-Tier 환경에서는 그렇게 구현할 수 있다. 그런데 클라이언트와 DB 사이에 WAS, AP 서버 등이 존재하는 n-Tier 아키텍처에서는 클라이언트가 특정 DB ____을 독점할 수 없다. 단위 작업을 마치면 DB 커넥션을 곧바로 ____에 반환해야 하므로 그 전에 SQL 조회 결과를 클라이언트에게 '모두' 전송하고 커서(cursor)를 닫아야 한다.(JAVA에서 Statement, ResultSet 객체). 그래서 구현하기 어렵다. 그래도 여전히 유효한데 5장에서 자세한 사항을 배운다.
부분범위 처리 원리를 활용해 상위 N개 집합을 빠르게 출력하도록 구현할 수 있다면, 인덱스로 엑세스할 전체 대상 레코드가 아무리 많아도 빠른 응답속도를 낼 수 있다. 그러기 위해선 인덱스를 이용해 소트 연산을 생략할 수 있어야 한다. 배치 I/O는 읽는 블록마다 건건이 I/O Call을 발생시키는 비효율을 줄이기 위해 고안한 기능이다. 이 기능이 작동하면 테이블 블록에 대한 디스크 I/O Call을 미뤘다가 읽을 블록이 일정량 쌓이면 한꺼번에 처리한다.
배치 I/O 기능이 작동하면 인덱스를 이용해서 출력하는 데이터 정렬 순서가 매번 다를 수 있다는 사실에 주목해야 한다. 실제 배치 I/O가 작동할 때는 데이터 출력 순서가 인덱스 정렬 순서와 다를 수 있다. 소트 생략 가능한 인덱스를 사용하더라도 ____ 기능이 작동하면 데이터 정렬 순서를 보장할 수 없다. 애초에 인덱스로 소트 연산을 생략할 수 없거나 SQL에 ORDER BY가 없으면, 랜덤 I/O 성능을 향상하는 이 기능을 옵티마이저가 기본적으로 사용하여 배치 I/O를 선택한다. 따라서 인덱스를 믿고 ORDER BY를 쓰지 않는 쿼리는 사용하지 않아야 한다. 옵티마이저가 Batch I/O를 채택할 수 있기 때문이다.
3.3 인덱스 스캔 효율화
운영환경에서 가능한 일반적인 튜닝 기법은 ____다.
인덱스 엑세스 조건은 인덱스 ____ 범위를 결정하는 조건절이다. 인덱스 수직적 탐색을 통해 스캔 시작점을 결정하는 데 영향을 미치고 인덱스 리프 블록을 스캔하다가 어디서 멈출지를 결정하는 데 영향을 미치는 조건절이다.
인덱스 필터 조건은 테이블로 ____할지를 결정하는 조건절이다.
인덱스를 이용하든, 테이블을 Full Scan하든, 테이블 엑세스 단계에서 처리되는 조건절은 모두 필터 조건이다. 테이블 필터 조건은 쿼리 수행 다음 단계로 전달하거나 최종 결과집합에 포함할지를 결정한다.
옵티마이저의 비용 계산 원리
비용 = 인덱스 ____ 탐색 비용 + 인덱스 ____ 탐색 비용 + 테이블 ____ 엑세스 비용 = 인덱스 루트와 브랜치 레벨에서 읽는 블록 수 + 인덱스 리프 블록을 스캔하는 과정에 읽는 블록 수 + 테이블 엑세스 과정에 읽는 블록 수
선행 컬럼이 모두 '=' 조건인 상태에서 첫 번째 나타나는 ____ 조건이 인덱스 스캔 범위를 결정한다. 이들 조건이 인덱스 ____ 조건이다. 나머지 인덱스 컬럼 조건은 모두 인덱스 ____ 조건이다.
아래 몇 가지 케이스를 제외하면, 인덱스 컬럼에 대한 조건절은 모두 ____ 조건에 표시된다. 첫 번째 나타나는 범위검색 조건 이후 조건절 컬럼은 스캔 범위를 줄이는 데 큰 역할을 못 하는데도 말이다.
좌변 컬럼을 가공한 조건절
왼쪽 '%' 또는 양쪽 '%' 기호를 사용한 like 조건절
같은 컬럼에 대한 조건절이 두 개 이상일 때, 인덱스 엑세스 조건으로 선택되지 못한 조건절
OR Expansion 또는 INLIST ITERATOR로 선택되지 못한 OR 또는 IN 조건절
따라서, 실행 계획과 상관없이 첫 번째 ____ 조건까지가 인덱스 ____ 조건이고 나머지는 ____ 조건이라고 이해하자.
BETWEEN 조건을 IN-LIST로 전환하면 IN-LIST 개수만큼 UNION ALL 브랜치가 생성되고 각 브랜치마다 모든 컬럼을 '=' 조건으로 검색하므로 앞서 선두 컬럼에 BETWEEN을 사용할 때와 같은 비효율이 사라진다.
Index ____ Scan 방식으로 유도해도 비슷한 효과를 얻을 수 있다.
IN-List 값들을 코드 테이블로 관리하고 있을 때는 NL방식 조인이나 서브쿼리로 구현하면 된다. NL 조인을 학습하고 나면 이해됨(4장)
BETWEEN 조건 때문에 리프 블록을 많이 스캔하는 비효율보다 IN-List 개수만큼 ____ 블록을 반복 탐색하는 비효율이 더 클 수도 있다. 따라서 인덱스 스캔 과정에 선택되는 레코드들이 서로 멀리 떨어져 있을 때만 유용하다는 사실을 기억해야 한다. BETWEEN 조건 때문에 인덱스를 비효율적으로 스캔하더라도 블록 I/O 측면에서는 대개 소량에 그치는 경우가 많다. 인덱스 리프 블록에는 테이블 블록과 달리 매우 많은 레코드가 담기기 때문이다.
Index ____ Scan을 활용하면 BETWEEN 조건을 굳이 조건절을 바꿔가며 IN-List 조건으로 변환하지 않아도 같은 효과를 낼 수 있다.
IN조건은 '='가 아니다. IN 조건이 '='이 되려면 ____ 방식으로 풀려야만 한다. 그렇지 않으면 IN 조건은 ____ 조건이다. IN조건이 ____ 조건으로서 의미있는 역할을 하려면, 해당 컬럼의 데이터가 아주 많아야 한다. 그렇지 않은 상황에서는 ____ 방식으로 처리되는 것이 오히려 낫다.
num_index_keys 힌트를 사용하여 IN-List를 엑세스 조건 또는 필터 조건으로 유도할 수 있다. 세 번째 인자 'n'은 n번째 컬럼까지만 ____ 조건으로 사용하라는 의미이다.
LIKE와 BETWEEN은 둘 다 범위 검색 조건으로서, 비효율 원리가 똑같이 적용되지만 데이터 분포와 조건절 값에 따라 인덱스 스캔량이 서로 다를 수 있다. ____보다 ____이 낫다.
날짜의 경우 LIKE '2025%' 202500 이 있을까봐, 202513이 있을까봐 더 스캔하게 되므로 ____으로 좀 더 범위를 제한하는 것이 낫다.
옵티마이저에 의한 OR Expansion 쿼리 변환이 기본적으로 작동하지 않으므로 인덱스 선두 컬럼에 대한 옵션 조건에 (is null)____ 조건을 사용해선 안된다. 옵션 조건 컬럼을 ____에 두고 인덱스를 구성해도 이를 사용할 수 없다. 이 방식의 유일한 장점은 옵션 조건 컬럼이 NULL 허용 컬럼이더라도 결과집합을 보장한다는 것 뿐이다. (옵션조건이란 필수값이 아닌 조회조건을 의미한다. 즉 사용자 입력에 따라 파라미터가 null일 수도 있는 조건)
SELECT*FROM 고객
WHERE (:cust_id ISNULLOR 고객ID = :cust_id)
AND 거래일자 BETWEEN :dt1 AND :dt2;
-- 이 경우 고객ID에 null이 들어오면 table full scan을 할 가능성이 높다.
즉, 이 얘기는 인덱스 선두 컬럼에 OR 조건을 사용하면 안 좋다는 이야기지. OR 조건을 쓸 때 성능 개선을 위해 어떻게 해야하는가에 대한 이야기가 아니다. 이런 경우에는 거래일자가 선두인 인덱스가 있는 게 좋다.
인덱스에 포함되지 않은 컬럼에 대한 옵션 조건은 어차피 테이블에서 필터링할 수 박에 없으므로 그럴 때는 OR 조건을 사용해도 무방하다. OR 조건을 활용한 옵션 조건 처리를 정리하면 다음과 같다.
인덱스 ____ 조건으로 사용 불가
인덱스 ____ 조건으로도 사용 불가
____ ____ 조건으로만 사용 가능
단, 인덱스 구성 컬럼 중 하나 이상이 Not Null 컬럼이면(모든 테이블 레코드가 인덱스에 저장되어 있음이 보장), 18c 부터 인덱스 ____ 조건으로 사용 가능
__ 조인이 대량 조인할 때 느린 이유도 랜덤I/O 때문이다. 이를 위해 ____ 조인과 __ 조인이 개발되었다.
DBMS는 일반적으로 _____ 인덱스를 사용한다.
____가 위쪽에 있고, ______를 거쳐 맨 아래 _____가 있다.
Root와 Branch 블록에 있는 각 레코드는 하위 블록에 대한 _____을 갖는다.
Root와 Branch 블록에는 주소값을 갖지 않는 _____라는 특별한 레코드가 있다.
Leaf 블록에 저장된 각 레코드는 _____ 순으로 정렬되어 있을 뿐만 아니라 테이블 레코드를 가리키는 주소값, 즉 _____를 갖는다.
ROWID = _____ + _____
데이터 블록 주소 = _____ + _____
블록 번호 : _____ 내에서 부여한 상대적 순번
로우 번호 : _____ 내 순번
인덱스 _____ 탐색 : 인덱스 스캔 시작지점을 찾는 과정 = 인덱스 레코드 중 조건을 만족하는 첫 번째 레코드를 찾는 과정이다. 즉, 인덱스 스캔 시작지점을 찾는 과정이다.
인덱스 _____ 탐색 : 데이터를 찾는 과정 = 찾고자 하는 데이터가 더 안 나타날 때까지 인덱스 리프 블록을 수평적으로 스캔한다.
조건절에 만족하는 데이터를 모두 찾기 위해서, ROWID를 얻기 위해서 수평적 탐색을 수행한다.
인덱스 선두 컬럼을 모두 _____ 조건으로 검색할 때는 어느 컬럼을 인덱스 앞쪽에 두든 블록 I/O 개수가 같으므로 성능도 똑같다. 즉 , 선두 컬럼이 모두 _____ 조건이면 수직적 탐색 과정의 비용이 같다는 것이다.
B*Tree 인덱스에서 어떤 값으로 탐색하더라도 인덱스 루트에서 리프 블록에 도달하기까지 읽는 블록 수가 _____.
인덱스 기본 사용법은 인덱스를 _____ Scan 하는 방법을 의미한다.
인덱스 컬럼(정확히는 _____ 컬럼)을 가공하지 않아야 인덱스를 정상적으로 사용할 수 있다. '인덱스를 정상적으로 사용한다'는 표현은 리프 블록에서 스캔 시작점을 찾아 거기서부터 스캔하다가 중간에 멈추는 것을 의미한다. 즉, 리프 블록 _____만 스캔하는 Index _____ Scan을 의미한다.
인덱스 컬럼을 가공해도 인덱스를 사용할 수는 있지만, 스캔 시작점을 찾을 수 없고 멈출 수도 없어 리프 블록 _____를 스캔해야만 한다. 즉, 일부가 아닌 전체를 스캔하는 Index _____ Scan 방식으로 작동한다.
Index _____ Scan은 인덱스에서 일정 범위를 스캔한다는 뜻이다. 일정 범위를 스캔하려면 시작지점과 끝지점이 있어야 한다. 인덱스 컬럼을 가공했을 때 인덱스 스캔 시작점을 찾을 수 없기 때문에 정상적으로 사용할 수 없다.
OR 조건식을 SQL 옵티마이저가 ________ 형태로 변환할 수 있는데 이를 'OR Expansion'이라고 한다.
__________ 힌트를 통해 'OR Expansion'를 유도할 수 있다.
IN 조건은 ___ 조건을 표현하는 다른 방식일 뿐이다. IN 조건절에 대해서는 SQL 옵티마이저가 IN-List Iterator 방식을 사용한다. IN-List 개수만큼 Index Range Scan을 반복하는 것이다. UNION ALL 방식으로 변환한 것과 같은 효과를 얻을 수 있다.
인덱스를 Range Scan 하기 위한 가장 첫 번째 조건은 인덱스 선두 컬럼이 조건절에 있어야 한다는 사실이다. 가공하지 않은 상태로 말이다.
문제는, 인덱스를 Range Scan 한다고 해서 항상 성능이 좋은 것은 아니라는 것이다.
'인덱스를 탄다'라는 표현은 '인덱스를 ______ 한다'와 같은 의미인 셈이다. 그런데 인덱스를 정말 잘 타는지는 인덱스 리프 블록에서 스캔하는 양을 따져봐야 알 수 있다.
인덱스 컬럼을 가공해도 인덱스를 사용할 순 있지만, 찾고자 하는 데이터가 전체 구간에 _____ 있기 때문에 Range Scan이 불가능하거나 비효율이 발생한다.
옵티마이저는 SQL에 ______가 있어도 정렬 연산을 따로 수행하지 않는다. 인덱스를 스캔하면서 출력한 결과 집합은 어차피 인덱스 컬럼 순으로 정렬되기 때문이다. 따라서 실행계획에 ____연산이 없다.
조건절이 아닌 ______ 또는 ________에서 컬럼을 가공함으로 인해 인덱스를 정상적으로 사용할 수 없는 경우도 종종 있다.
인덱스를 이용해 정렬 연산 없이 최소 또는 최대값을 빠르게 찾을 때 인덱스 리프블록의 왼쪽(MIN) 또는 오른쪽(MAX)에서 레코드 하나(FIRST ROW)만 읽고 멈춘다.
인덱스는 문자열 기준으로 정렬돼 있는데 이를 __값으로 바꾼 값 기준으로 최소 또는 최대값, ORDER BY를 요구하면 정렬 연산을 생략할 수 없다.
오라클은 자동으로 ____ 처리해준다.
오라클에서 __형과 __형이 만나면 __형이 이긴다. 숫자형 컬럼 기준으로 문자형 컬럼을 변환한다는 뜻이다. 연산자가 __ 일 때는 다르다. LIKE 자체가 문자열 비교 연산자이므로 이때는 문자형 기준으로 숫자형 컬럼이 변환된다. __형 컬럼을 LIKE 조건으로 검색하면 자동 형변환이 발생해 인덱스 ____조건으로 사용되지 못한다.
날짜형과 문자형이 만나면 __형이 이긴다.
DECODE(A, B, C, D)를 처리 할 때 'A = B' 이면 C를 반환하고, 아니면 D를 반환한다. 이때 반환값의 데이터 타입은 __에 의해 결정된다. 세 번째 인자가 NULL 값이면 네 번 째 인자가 숫자형이어도 문자열로 변환하고, 문자열 기준으로 MAX() 를 수행하게 된다. 950보다 5000이 크다고 판단하게 된다.
SQL 성능 원리를 잘 모르는 개발자는 TO_CHAR, TO_DATE, TO_NUMBER 같은 형변환 함수를 의도적으로 생략하곤 한다. 이들 함수를 생략하면 연산횟수가 줄어 성능이 더 좋지 않을까 생각하기 때문이다. SQL 성능은 그런 데서 결정되는 게 아니라 블록 I/O를 줄일 수 있느냐 없느냐에서 결정된다. 형변환 함수를 생략한다고 연산 횟수가 주는 것도 아니다. 개발자가 형변환 함수를 생략해도 옵티마이저가 자동으로 생성한다.
Index Range Scan 이외에도 Index __ Scan, Index __ Scan, Index __ Scan, Index __ Full Scan 등이 있다.
Index Range Scan은 인덱스 루트에서 리프 블록까지 수직적으로 탐색한 후에 필요한 범위만 스캔한다.
선두 컬럼을 ________ 상태로 조건절에 사용하면 Index Range Scan이 무조건 가능하다. 그러므로 성능은 인덱스 스캔 범위, 테이블 엑세스 횟수를 얼마나 줄일 수 있느냐로 결정된다.
Index __ Scan은 __적 탐색없이 인덱스 리프 블록을 처음부터 끝까지 __적으로 탐색하는 방식이다.
Index __ Scan은 대개 데이터 검색을 위한 최적의 인덱스가 없을 때 차선으로 선택된다.
대용량 테이블이어서 옵티마이저는 Table Full Scan을 고려하지만, 대용량 테이블의 경우 Table Full Scan이 부담스러워서 옵티마이저는 인덱스 활용을 고려하지 않을 수 없다.
/*+ ________ */ 힌트를 사용하면 옵티마이저가 모드를 바꿔 인덱스 Full Scan을 고려한다. 이는 인덱스를 활용하므로 Sort 연산 생략 효과를 가져온다.
Index __ Scan은 수직적 탐색만으로 데이터를 찾는 스캔 방식으로서 Unique 인덱스를 '=' 조건으로 탐색하는 경우에 작동한다.
__ 인덱스가 존재하는 컬럼은 중복 값이 입력되지 않게 DBMS가 데이터 정합성을 관리한다. 따라서 해당 인덱스 키 컬럼을 모두 '=' 조건으로 검색할 때는 데이터를 한 건 찾는 순간 더 이상 탐색할 필요가 없다.
Unique __ 인덱스에 대해 일부 컬럼으로만 검색할 때도 Index Range Scan이 나타난다.
옵티마이저는 Table Full Scan보다 I/O를 줄일 수 있거나 정렬된 결과를 쉽게 얻을 수 있다면, Index __ Scan을 사용하기도 한다.
오라클은 인덱스 선두 컬럼이 조건절에 없어도 인덱스를 활용하는 새로운 스캔 방식이 Index __ Scan이다. 이 스캔 방식을 조건절에 빠진 인덱스 __ 컬럼의 Distinct Value 개수가 적고 __ 컬럼의 Distinct Value 개수가 많을 때 유용하다. 예를 들어 고객 테이블에서 Distinct Value가 적은 컬럼을 '성별'이라고 할 수 있다.
Index __ Scan은 루트 또는 브랜치 블록에서 읽은 컬럼 값 정보를 이용해 조건절에 부합하는 레코드를 포함할 '가능성이 있는' 리프 블록만 골라서 엑세스하는 스캔 방식이다.
인덱스 선두 컬럼이 없을 때만 Index Skip Scan이 작동하는 것은 아니다.
선두 컬럼에 대한 조건절은 있고, __ 컬럼에 대한 조건절이 없는 경우에도 Skip Scan을 사용할 수 있다.
/*+ ________(A 일별업종별거래_PK) */
Index Skip Scan을 사용한다면, 업종유형코드 = '01'인 구간에서 기준일자가 '20080501'보다 크거나 같고 '20080531'보다 작거나 같은 레코드를 '포함할 가능성이 있는 리프 블록만' 골라서 엑세스할 수 있다.
선두컬럼이 부등호, BETWEEN, LIKE 같은 범위검색 조건일 때도 Index __ Scan을 사용할 수 있다.
Index Range Scan을 사용한다면, 기준일자 BETWEEN 조건을 만족하는 인덱스 구간을 모두 스캔해야 한다. Index __ Scan을 사용한다면, 기준일자 BETWEEN 조건을 만족하는 인덱스 구간에서도 업종유형코드 = '01'인 레코드를 포함할 가능성이 있는 리프 블록만 골라서 엑세스할 수 있다. 이처럼 Index Range Scan이 불가능하거나 효율적이지 못한 상황에서 Index __ Scan이 종종 빛을 발한다.
인덱스는 기본적으로 최적의 Index Range Scan을 목표로 설계해야 하며, 수행 횟수가 적은 SQL을 위해 인덱스를 추가하는 것이 비효율적일 때 이들 스캔 방식을 차선책으로 활용하는 전략이 바람직하다.
Index __ __Scan이 Index __ Scan 보다 빠른 이유는, 논리적인 인덱스 트리 구조를 무시하고 인덱스 세그먼트 전체를 ______ I/O 방식으로 스캔하기 때문이다. 관련 힌트 : index_ffs, no_index_ffs
Index Fast Full Scan은 물리적으로 ____에 저장된 순서대로 인덱스 리프 블록들을 읽어들인다.
결과집합이 인덱스 키 순서대로 정렬되지 않는다. 쿼리에 사용한 컬럼이 __ 인덱스에 포함돼 있을 때만 사용할 수 있다는 점도 기억할 필요가 있다.
Index Range Scan 또는 Index Full Scan과 달리, 인덱스가 ____ 돼 있지 않더라도 병렬 쿼리가 가능한 것도 중요한 특징 중 하나이다. 병렬 쿼리 시에는 ______ I/O 방식을 사용하기 때문에 속도가 더 빨라진다.
Table Full Scan은 읽어야 할 익스텐트 목록을 익스텐트 맵에서 얻는다. Index Fast Full Scan도 똑같은 방식을 사용한다.
Index Fast Full Scan 특징
____ 전체를 스캔
____ 순서 보장 안 됨
________ I/O
____ 가능
인덱스에 포함된 컬럼으로만 조회할 때 사용 가능
Index Full Scan 특징
인덱스 (논리적) 구조를 따라 스캔
결과집합 순서 보장
______ I/O
(____ 돼 있지 않다면) 병렬스캔 불가
인덱스에 포함되지 않은 컬럼 조회시에도 사용 가능
Index Range Scan _______은 인덱스를 뒤에서부터 앞쪽으로 스캔하기 때문에 내림차순으로 정렬된 결과집합을 얻는다는 점만 다르다.
SQL이 참조하는 컬럼을 인덱스가 모두 포함하는 경우가 아니면, 인덱스를 스캔한 후에 반드시 테이블을 엑세스한다. TABLE ACCESS BY INDEX ROWID라고 표시된 부분이 여기에 해당한다.
인덱스 ROWID 는 물리적 주소보다 논리적 주소에 가깝다. 물리적으로 직접 연결되지 않고 테이블 레코드를 찾아가기 위한 논리적 주소 정보를 담고 있기 때문이다.
프로그래밍 언어에서 포인터는 메모리 주소값을 담는 변수를 말한다. 물리적으로 직접 연결된 구조나 다름없다. 메모리 상에서의 위치 정보인 포인터를 생각하며 인덱스 ROWID를 물리적 주소로 이해했다면 잘못 이해한 것이다. 인덱스 ROWID는 포인터가 아니다. 인덱스는 ROWID는 논리적 주소다. 디스크 상에서 테이블 레코드를 찾아가기 위한 위치 정보를 담는다. 포인터가 아니며, 테이블 레코드와 물리적으로 직접 연결된 구조는 더더욱 아니다.
메인 메모리 DB(MMDB)는 데이터를 모두 메모리에 로드해 놓고 메모리를 통해서만 I/O를 수행하는 DB라고 할 수 있다.
잘 튜닝된 OLTP성 데이터베이스 시스템이라면 버퍼캐시 히트율이 99% 이상이지만 그래도 MMDB만큼 빠르지는 않다. MMDB의 경우 인스턴스 가동 시 디스크에 저장된 데이터를 버퍼캐시로 로딩하고 이어서 인덱스를 생성한다. 이 때 인덱스는 디스크 상의 주소가 아닌 메모리상의 주소정보, 즉 포인터를 갖는다. 따라서 인덱스를 경유해 테이블을 엑세스하는 비용이 오라클에 비해 현저히 낮다.
오라클은 테이블 블록이 수시로 버퍼캐시에서 밀려났다가 캐싱되며, 그때마다 다른 공간에 캐싱되기 때문에 인덱스에서 포인터로 직접 연결할 수 없는 구조다. 메모리 주소 정보(포인터)가 아닌 디스크 주소 정보(DBA, Data Block Address)를 이용해 해시 알고리즘으로 버퍼 블록을 찾아간다.
읽고자 하는 DBA를 해시 함수에 입력해서 해시 체인을 찾고 거기서 버퍼 헤더를 찾는다. 거기서 얻은 포인터로 버퍼 블록을 찾아간다.
인덱스로 테이블 블록을 엑세스할 때는 리프 블록에서 얻은 ROWID를 분해해서 DBA 정보를 얻고, 테이블을 Full Scan할 때는 익스텐트 맵을 통해 읽을 블록들의 DBA 정보를 얻는다.
모든 데이터가 캐싱돼 있더라도 테이블 레코드를 찾기 위해 매번 DBA 해싱과 래치 획득 과정을 반복해야 한다. 동시 엑세스가 심할 때는 캐시 버퍼 체인 래치와 버퍼 Lock에 대한 경합까지 발생한다. 이처럼 인덱스 ROWID를 이용한 테이블 엑세스는 생각보다 고비용 구조이다.
클러스터링 팩터(Clustering Factor, CF)는 특정 컬럼을 기준으로 같은 값을 갖는 데이터가 서로 모여있는 정도를 의미한다. CF가 좋은 컬럼에 생성한 인덱스는 검색 효율이 매우 좋다. 즉, 테이블 엑세스량에 비해 블록 I/O가 적게 발생한다.
인덱스 ROWID로 테이블을 엑세스할 때, 오라클은 래치 획득과 해시 체인 스캔 과정을 거쳐 어렵게 찾아간 테이블 블록에 대한 포인터(메모리 주소값)를 바로 해제하지 않고 일단 유지한다. 이를 '버퍼 Pinning' 이라고 한다. 이 상태에서 다음 인덱스 레코드를 읽었는데, 마침 직전과 같은 테이블 블록을 가리킨다. 그러면 래치 획득과 해시 체인 스캔 과정을 생략하고 바로 테이블 블록을 읽을 수 있다. 논리적인 블록 I/O 과정을 생략할 수 있는 것이다.
인덱스 ROWID를 이용한 테이블 엑세스는 생각보다 고비용 구조다. 따라서 읽어야 할 데이터가 일정량을 넘는 순간, 테이블 전체를 스캔하는 것보다 오히려 느려진다.
추출 건수가 늘면서 인덱스 스캔량이 느는 데서도 영향을 받지만, 테이블 랜덤 엑세스가 미치는 영향에 비교할 바가 아니다.
인덱스를 이용한 테이블엑세스가 Table Full Scan보다 더 느려지게 만드는 핵심 요인 두가지는 다음과 같다.
Table Full Scan은 스퀀셜 엑세스인 반면, 인덱스 ROWID를 이용한 테이블 엑세스는 랜덤 엑세스 방식이다.
Table Full Scan은 Multiblock I/O인 반면, 인덱스 ROWID를 이용한 테이블 엑세스는 Single Block I/O 방식이다.
인덱스 사용 시 손익분기점 개념은 온라인 트랜잭션을 처리하는 프로그램과 DW/OLAP/배치 프로그램 튜닝의 특징을 구분 짓는 핵심 개념이다.
온라인 프로그램은 보통 소량 데이터를 읽고 갱신하므로 인덱스를 효과적으로 활용하는 것이 무엇보다 중요하다. 조인도 대부분 NL 방식을 이용한다. NL조인은 인인덱스를 이용하는 조인 방식이다.
대량 데이터를 읽고 갱신하는 배치(batch) 프로그램은 항상 전체범위 처리 기준으로 튜닝해야 한다. 대량 데이터를 빠르게 처리하려면, 인덱스와 NL 조인보다 Full Scan과 해시 조인이 유리하다.
대량 배치 프로그램에선 인덱스보다 Full Scan이 효과적이지만, 초대용량 테이블을 Full Scan 하면 상당히 오래 기다려야 하고 시스템에 주는 부담도 적지 않다. 따라서 배치 프로그램에서는 파티션 활용 전략이 매우 중요한 튜닝 요소이고, 병렬 처리까지 더할 수 있으면 금상첨화다.
관리적 측면을 배제하고 성능 측면에서만 보면 테이블을 파티셔닝하는 이유는 결국 Full Scan을 빠르게 처리하기 위해서다. 모든 성능 문제를 인덱스로 해결하려 해선 안 된다. 큰 테이블에서 아주 적은 일부 데이터를 빨리 찾고자 할 때 주로 사용한다.
테이블 엑세스 단계 필터 조건에 의해 버려지는 레코드가 많을 때, 기존 인덱스에 WHERE절에 있는 컬럼을 추가하는 것만으로 큰 효과를 얻을 수 있따. 인덱스 스캔량은 줄지 않지만, 테이블 랜덤 엑세스 회수를 줄일 수 있다.
인덱스만 읽어서 처리하는 쿼리를 Covered 쿼리하고 부르며 그 쿼리에 사용한 인덱스를 Covered 인덱스라고 부른다.
SQL Server 2005 버전에 추가된 Include 인덱스 기능이 있다. 인덱스 키 외에 미리 저장한 컬럼을 리프 레벨에 함께 저장하는 기능이다. 인덱스를 생성할 때 include (col) 옵션을 추가해주면 된다. 테이블 랜덤 엑세스 횟수를 줄이는 용도로만 사용한다.
IOT(Index-Organized Table)는 테이블을 인덱스 구조로 생성한 것이다. MS-SQL Server는 Clustered Index라고 부른다.
일반 테이블은 힙 구조 테이블이며 대개 생략하지만 테이블 생성 시 organization heap 옵션을 명시할 수도 있다. 반면, IOT는 인덱스 구조 테이블이므로 정렬 상태를 유지하며 데이터를 입력한다. IOT는 인위적으로 클러스터링 팩터를 좋게 만드는 방법 중 하나다.
예를 들어, 어떤 회사에 영업사원이 100명이라고 가정하자. 영원사업들의 일별 실적을 집계하는 테이블이 있는데 한 블록에 100개 레코드가 담긴다. 그러면 매일 한 블록씩 1년이면 365개 블록이 생긴다. 사번+일자로 SUM을 수행하는 쿼리가 자주 수행된다고 했을 때 사번 기준의 클러스터링 팩터가 안 좋으므로 조회건 수 만큼 블록 I/O가 발생하게 된다. 이 때 사번이 첫 번째 정렬 기준이 되도록 IOT를 구성해주면 적은 블록만 읽고 처리할 수 있다. oraganization index 옵션을 사용하여 테이블을 생성하면 된다.
클러스터 테이블에는 인덱스 클러스터와 해시 클러스터 두 가지가 있다.
인덱스 클러스터 테이블은 클러스터 키 값이 같은 레코드를 한 블록에 모아서 저장하는 구조다.
여러 테이블 레코드를 같은 블록에 저장할 수도 있는데, 이를 '다중 테이블 클러스터'라고 부른다. 클러스터에 테이블을 담기 전에 클러스터 인덱스를 반드시 정의해야 한다. 클러스터 인덱스는 데이터 검색 용도로 사용할 뿐만 아니라 데이터가 저장될 위치를 찾을 때도 사용하기 때문이다.
일반 테이블에 생성한 인덱스 레코드는 테이블 레코드와 1:1 대응 관계를 갖지만, 클러스터 인덱스는 테이블 레코드와 1:M 관계를 갖는다. 따라서 클러스터 인덱스의 키값은 항상 Unique하다.(=중복값이 없다.)
클러스터에 도달해서는 시퀀셜 방식으로 스캔하기 때문에 넓은 범위를 읽더라도 비효율이 없다는 게 핵심원리다.
해시 클러스터는 인덱스를 사용하지 않고 해시 알고리즘을 사용해 클러스터를 찾아간다는 점만 다르다.
3.2 부분범위 처리 활용
DBMS가 클라이언트에게 데이터를 전송할 때 일정량씩 나누어 전송한다. 전체 결과집합 중 아직 전송하지 않은 분량이 많이 남아있어도 서버 프로세스는 클라이언트로부터 추가 Fetch Call을 받기 전까지 그대로 멈춰 서서 기다린다.
DBMS가 데이터를 모두 읽어 한 번에 전송하지 않고 먼저 읽는 데이터부터 일정량(Array Size)을 전송하고 멈추기 때문이다. 데이터를 전송하고 나면 서버 프로세스는 CPU를 OS에 반환하고 대기 큐에서 잠을 잔다. 다음 Fetch Call을 받으면 대기 큐에서 나와 그다음 데이터부터 일정량을 읽어서 전송하고 또다시 잠을 잔다. 이처럼 전체 쿼리 결과집합을 쉼 없이 연속적으로 전송하지 않고 사용자로부터 Fetch Call이 있을 때마다 일정량씩 나누어 전송하는 것을 이른바 '부분범위 처리'라고 한다. 데이터를 전송하는 단위인 Array Size는 클라이언트 프로그램에서 설정한다. JAVA에서는 기본적값이 10이며, Statement 객체 setFetchSize 메소드를 통해 설정을 변경할 수 있다.
rs.next() 호출 시 Fetch Call을 통해 전송받은 데이터 10건을 클라이언트 캐시에 저장하고 이후 캐시에 저장한 데이터를 모두 소진한 후 rs.next()가 호출되면 추가 Fetch Call을 통해 10건을 전송받는다. 따라서 rs.next() 사이에 있는 JAVA 프로그램 로직이 오래 걸릴 이유는 없다.
order by가 있고 해당 컬럼이 선두인 index가 없으면 정렬을 마치고서야 클라이언트에게 데이터 전송을 시작한다. 즉 전체범위 처리다. 정렬 컬럼이 선두인 index가 있으면 부분범위 처리가 가능하다. 인덱스는 항상 정렬된 상태를 유지하므로 전체 데이터를 정렬하지 않고도 정렬된 상태의 결과집합을 바로 전송할 수 있기 때문이다.
대량 데이터를 파일로 내려받는다면 어차피 데이터를 모두 전송해야 하므로 가급적 Array Size를 크게 설정해야한다. 그러면 Fetch Call을 줄일 수 있다. 앞쪽 일부 데이터만 Fetch하다가 멈추는 프로그램이라면 Array Size를 작게 설정하는 것이 유리하다.
Fetch Call의 특성을 이용해 중간에 멈췄다가 사용자의 추가 요청이 있을 때마다 데이터를 가져오도록 구현하고 안 하고는 클라이언트 프로그램을 개발하는 개발자의 몫이다.
OLTP 시스템은 말 그대로 온라인 트랜잭션을 처리하는 시스템을 말한다., 온라인 트랜잭션은 일반적으로 소량 데이터를 읽고 갱신한다.
OLTP 시스템이 수천수만 건을 조회하는 경우도 있다. 이 때 부분범위처리로 성능 개선을 할 수 있다. 문제는 앞쪽 일부만 출력하고 멈출 수 잇는가이다. 토드나 오렌지같은 쿼리 툴은 이미 그렇게 구현돼 있다. 이들처럼 클라이언트 프로그램이 DB 서버에 직접 접속하는 2-Tier 환경에서는 그렇게 구현할 수 있다. 그런데 클라이언트와 DB 사이에 WAS, AP 서버 등이 존재하는 n-Tier 아키텍처에서는 클라이언트가 특정 DB 커넥션을 독점할 수 없다. 단위 작업을 마치면 DB 커넥션을 곧바로 커넥션 풀에 반환해야 하므로 그 전에 SQL 조회 결과를 클라이언트에게 '모두' 전송하고 커서(cursor)를 닫아야 한다.(JAVA에서 Statement, ResultSet 객체). 그래서 구현하기 어렵다. 그래도 여전히 유효한데 5장에서 자세한 사항을 배운다.
부분범위 처리 원리를 활용해 상위 N개 집합을 빠르게 출력하도록 구현할 수 있다면, 인덱스로 엑세스할 전체 대상 레코드가 아무리 많아도 빠른 응답속도를 낼 수 있다. 그러기 위해선 인덱스를 이용해 소트 연산을 생략할 수 있어야 한다. 배치 I/O는 읽는 블록마다 건건이 I/O Call을 발생시키는 비효율을 줄이기 위해 고안한 기능이다. 이 기능이 작동하면 테이블 블록에 대한 디스크 I/O Call을 미뤘다가 읽을 블록이 일정량 쌓이면 한꺼번에 처리한다.
배치 I/O 기능이 작동하면 인덱스를 이용해서 출력하는 데이터 정렬 순서가 매번 다를 수 있다는 사실에 주목해야 한다. 실제 배치 I/O가 작동할 때는 데이터 출력 순서가 인덱스 정렬 순서와 다를 수 있다. 소트 생략 가능한 인덱스를 사용하더라도 배치 I/O 기능이 작동하면 데이터 정렬 순서를 보장할 수 없다. 애초에 인덱스로 소트 연산을 생략할 수 없거나 SQL에 ORDER BY가 없으면, 랜덤 I/O 성능을 향상하는 이 기능을 옵티마이저가 기본적으로 사용하여 배치 I/O를 선택한다. 따라서 인덱스를 믿고 ORDER BY를 쓰지 않는 쿼리는 사용하지 않아야 한다. 옵티마이저가 Batch I/O를 채택할 수 있기 때문이다.
3.3 인덱스 스캔 효율화
운영환경에서 가능한 일반적인 튜닝 기법은 인덱스 컬럼 추가다.
인덱스 엑세스 조건은 인덱슼 스캔 범위를 결정하는 조건절이다. 인덱스 수직적 탐색을 통해 스캔 시작점을 결정하는 데 영향을 미치고 인덱스 리프 블록을 스캔하다가 어디서 멈출지를 결정하는 데 영향을 미치는 조건절이다.
인덱스 필터 조건은 테이블로 엑세스할지를 결정하는 조건절이다.
인덱스를 이용하든, 테이블을 Full Scan하든, 테이블 엑세스 단계에서 처리되는 조건절은 모두 필터 조건이다. 테이블 필터 조건은 쿼리 수행 다음 단계로 전달하거나 최종 결과집합에 포함할지를 결정한다.
옵티마이저의 비용 계산 원리
비용 = 인덱스 수직적 탐색 비용 + 인덱스 수평적 탐색 비용 + 테이블 랜덤 엑세스 비용 = 인덱스 루트와 브랜치 레벨에서 읽는 블록 수 + 인덱스 리프 블록을 스캔하는 과정에 읽는 블록 수 + 테이블 엑세스 과정에 읽는 블록 수
선행 컬럼이 모두 '=' 조건인 상태에서 첫 번째 나타나는 범위검색 조건이 인덱스 스캔 범위를 결정한다. 이들 조건이 인덱스 엑세스 조건이다. 나머지 인덱스 컬럼 조건은 모두 인덱스 필터 조건이다.
아래 몇 가지 케이스를 제외하면, 인덱스 컬럼에 대한 조건절은 모두 엑세스 조건에 표시된다. 첫 번째 나타나는 범위검색 조건 이후 조건절 컬럼은 스캔 범위를 줄이는 데 큰 역할을 못 하는데도 말이다.
좌변 컬럼을 가공한 조건절
왼쪽 '%' 또는 양쪽 '%' 기호를 사용한 like 조건절
같은 컬럼에 대한 조건절이 두 개 이상일 때, 인덱스 엑세스 조건으로 선택되지 못한 조건절
OR Expansion 또는 INLIST ITERATOR로 선택되지 못한 OR 또는 IN 조건절
따라서, 실행 계획과 상관없이 첫 번째 범위검색 조건까지가 인덱스 엑세스 조건이고 나머지는 필터 조건이라고 이해하자.
BETWEEN 조건을 IN-LIST로 전환하면 IN-LIST 개수만큼 UNION ALL 브랜치가 생성되고 각 브랜치마다 모든 컬럼을 '=' 조건으로 검색하므로 앞서 선두 컬럼에 BETWEEN을 사용할 때와 같은 비효율이 사라진다.
Index Skip Scan 방식으로 유도해도 비슷한 효과를 얻을 수 있다.
IN-List 값들을 코드 테이블로 관리하고 있을 때는 NL방식 조인이나 서브쿼리로 구현하면 된다. NL 조인을 학습하고 나면 이해됨(4장)
BETWEEN 조건 때문에 리프 블록을 많이 스캔하는 비효율보다 IN-List 개수만큼 브랜치 블록을 반복 탐색하는 비효율이 더 클 수도 있다. 따라서 인덱스 스캔 과정에 선택되는 레코드들이 서로 멀리 떨어져 있을 때만 유용하다는 사실을 기억해야 한다. BETWEEN 조건 때문에 인덱스를 비효율적으로 스캔하더라도 블록 I/O 측면에서는 대개 소량에 그치는 경우가 많다. 인덱스 리프 블록에는 테이블 블록과 달리 매우 많은 레코드가 담기기 때문이다.
Index Skip Scan을 활용하면 BETWEEN 조건을 굳이 조건절을 바꿔가며 IN-List 조건으로 변환하지 않아도 같은 효과를 낼 수 있다.
IN조건은 '='가 아니다. IN 조건이 '='이 되려면 IN-List Iterator 방식으로 풀려야만 한다. 그렇지 않으면 IN 조건은 필터 조건이다. IN조건이 엑세스 조건으로서 의미있는 역할을 하려면, 해당 컬럼의 데이터가 아주 많아야 한다. 그렇지 않은 상황에서는 필터 방식으로 처리되는 것이 오히려 낫다.
num_index_keys 힌트를 사용하여 IN-List를 엑세스 조건 또는 필터 조건으로 유도할 수 있다. 세 번째 인자 'n'은 n번째 컬럼까지만 엑세스 조건으로 사용하라는 의미이다.
LIKE와 BETWEEN은 둘 다 범위 검색 조건으로서, 비효율 원리가 똑같이 적용되지만 데이터 분포와 조건절 값에 따라 인덱스 스캔량이 서로 다를 수 있다. LIKE보다 BETWEEN이 낫다.
날짜의 경우 LIKE '2025%' 202500 이 있을까봐, 202513이 있을까봐 더 스캔하게 되므로 BETWEEN으로 좀 더 범위를 제한하는 것이 낫다.
옵티마이저에 의한 OR Expansion 쿼리 변환이 기본적으로 작동하지 않으므로 인덱스 선두 컬럼에 대한 옵션 조건에 (is null)OR 조건을 사용해선 안된다. 옵션 조건 컬럼을 선두에 두고 인덱스를 구성해도 이를 사용할 수 없다. 이 방식의 유일한 장점은 옵션 조건 컬럼이 NULL 허용 컬럼이더라도 결과집합을 보장한다는 것 뿐이다. (옵션조건이란 필수값이 아닌 조회조건을 의미한다. 즉 사용자 입력에 따라 파라미터가 null일 수도 있는 조건)
SELECT*FROM 고객
WHERE (:cust_id ISNULLOR 고객ID = :cust_id)
AND 거래일자 BETWEEN :dt1 AND :dt2;
-- 이 경우 고객ID에 null이 들어오면 table full scan을 할 가능성이 높다.
즉, 이 얘기는 인덱스 선두 컬럼에 OR 조건을 사용하면 안 좋다는 이야기지. OR 조건을 쓸 때 성능 개선을 위해 어떻게 해야하는가에 대한 이야기가 아니다. 이런 경우에는 거래일자가 선두인 인덱스가 있는 게 좋다.
인덱스에 포함되지 않은 컬럼에 대한 옵션 조건은 어차피 테이블에서 필터링할 수 박에 없으므로 그럴 때는 OR 조건을 사용해도 무방하다. OR 조건을 활용한 옵션 조건 처리를 정리하면 다음과 같다.
인덱스 엑세스 조건으로 사용 불가
인덱스 필터 조건으로도 사용 불가
테이블 필터 조건으로만 사용 가능
단, 인덱스 구성 컬럼 중 하나 이상이 Not Null 컬럼이면(모든 테이블 레코드가 인덱스에 저장되어 있음이 보장), 18c 부터 인덱스 필터 조건으로 사용 가능
It is a Type-Pool which has all of the TYPES statements for the ALV. You can specify its use by adding the TYPE-POOLS statement to your program.
SLIS를 type-pool로 선언하여 프로그램에서 사용하겠다는 의미. TYPE-POOL이란 SAP에서 제공하는 각종 타입 및 Constants가 선언되어 있는 그룹이다.
TABLES *table_wa.
This statement declares an additionaltable work area*table_wa, whose data type, like that of the regularTABLESstatement with itsflatstructured data typetable_wa, is taken from ABAP Dictionary.
The additional table work area can be used just like the regular table work area. This applies in particular to obsoletedatabase accesses.
For many entry fields, but not all, SAP provides a search function called a Matchcode. Matchcodes allow you to select a value from a list or search for a value by categories of data if there are many possibilities.
EX) Search Help SD_DEBI (Customers: SD collective search help)
MEMORY ID
when u are passing on values from one program to another program then we can use memory ID's
Program1
EXPORT EXCH1 TO MEMORY ID 'EXCH'.
Program2
IMPORT EXCH1 FROM MEMORY ID 'EXCH'.
EXCH1 is the variable name whose value u are exporting and importing from..
This is only valid till the particular session,
dont forget to award points if found helpful
NO-EXTENSION: Multiple 입력가능한 화살표 버튼 제거. NO INTERVALS : SELECT-OPTIONS의 간격 기능 제거
* MODIF ID * - 화면 구성요소의 속성(입력 가능, 불가능 등)을 일괄적으로 변경하기 위해 * 해당 변수들을 GROUP으로 묶어줌 * - AT SELECTION-SCREEN OUTPUT 에서 사용
AT SELECTION-SCREEN OUTPUT· 실행 시점: 선택 화면이 사용자에게 처음 표시되기 직전에 실행됨
The assignments to input fields in the event blockAT SELECTION-SCREEN OUTPUTalways affect the selection screen and overwrite the user input from previous displays of the same selection screen. Assignments in the event blocksLOAD-OF-PROGRAMorINITIALIZATION, on the other hand, only have an effect the first time the program starts.
difference between at selection screen and at selection screen output.
AT SELECTION SCREEN:
when user enters the values in the fields of the selection screen and clicks on execution button,this event gets triggered.this event is basically for checking the value entered by the user for the field of the selection screen i.e data validity checking.this event is for entire selection screen.
AT SELECTION SCREEN OUTPUT:
This event is executed at PBO of the selection screen every time the user presses
ENTER - in contrast to INITIALIZATION . Therefore, this event is not suitable for setting selection screen default values.
Also, since AT SELECTION-SCREEN OUTPUT is first executed after the variant is imported (if a variant is used)
and after adopting any values specified under SUBMIT in the WITH clause, changing the report parameters
or the selection options in AT SELECTION-SCREEN OUTPUT would destroy the specified values.
Here, however, you can use LOOP AT SCREEN or MODIFY SCREEN to change the input/output attributes of selection screen fields.
Example
Output all fields of the SELECT-OPTION NAME highlighted:
SELECT-OPTIONS NAME FOR SY-REPID MODIF ID XYZ.
....
AT SELECTION-SCREEN OUTPUT.
LOOP AT SCREEN.
CHECK SCREEN-GROUP1 = 'XYZ'.
SCREEN-INTENSIFIED = '1'.
MODIFY SCREEN.
ENDLOOP.
The addition MODIF ID XYZ to the key word SELECT-OPTIONS
assigns all fields of the selection option NAME to a group you can read in the field SCREEN-GROUP1 .
At PBO of the selection screen, all these fields are then set to highlighted
SY-CPROG : Calling Program, 현재 프로그램(Function, Class method 등)을 호출한 프로그램의 ID
SLIS_LAYOUT_ALV: syructure layout of the report
It is used to for defining the layout of your ALV report
like
ls_layout TYPE slis_layout_alv.
and we define different paramters of this layout like
ls_layout-group_change_edit = 'X'.
ls_layout-colwidth_optimize = 'X'.
ls_layout-zebra = 'X'.
ls_layout-detail_popup = 'X'.
ls_layout-get_selinfos = 'X'.
ls_layout-max_linesize = '200'.
SLIS_T_FIELDCAT_ALV
This internal table contains the field attributes. This internal table can be populated automatically by using ‘REUSE_ALV_FIELDCATALOG_MERGE’.
It is nothing but a type group to declare fieldcat table for alv display. The fieldcat is nothing but the output display properties of each field in the alv report.
SLIS_T_EVENT: This is to set the events (for display the header data).
SLIS_T_LISTHEADER
slis_t_listheadergives the heading of a list.It is composed of the list title in the title bar and of any column headings. These can be maintained as part of the text elements of an ABAP program for the standard page header.
BSID : 고객에 대한 미결(채권)을 관리하는 테이블.(반제가 되면 삭제되고, BSAD로 이관)
SELECT A~VBELN " SALES ORDER DOCUMENT
, A~POSNR " SALES ORDER ITEM
, C~VBELN " DEVLIVERY DOCUMENT
, C~POSNR " DELIVERY ITEM
, E~VBELN " BILLING DOCUMENT
, E~POSNR " BILLING ITEM
, F~FKSTO " BILLING CANCEL FLAG
, F~SFAKN " CANCELED BILLING DOC
FROM VBAP AS A
LEFTOUTERJOIN VBFA AS B ON B~VBELV = A~VBELN
AND B~POSNV = A~POSNR
AND B~VBTYP_N ='J'LEFTOUTERJOIN LIPS AS C ON C~VBELN = B~VBELN
AND C~POSNR = B~POSNN
LEFTOUTERJOIN VBFA AS D ON D~VBELV = C~VBELN
AND D~POSNV = C~POSNR
AND ( D~VBTYP_N ='M'OR D~VBTYP_N ='N' )
LEFTOUTERJOIN VBRP AS E ON E~VBELN = D~VBELN
AND E~POSNR = D~POSNN
LEFTOUTERJOIN VBRK AS F ON F~VBELN = E~VBELN
WHERE
VBFA 매핑 테이블을 통해 SD 문서의 Sales Order , Delivery, Billing 연결
다만, 매출조정이 Sales Order 에서 Delivery 없이 Billing 처리되거나 반품오더 처럼 Billing을 Order 기준으로 하는 경우는 가져오지 못함