1. SQL이 느린 이유
- SQL이 느린 이유는 디스크 I/O 때문이다.
- OS 또는 I/O 서브시스템이 I/O를 처리하는 동안 프로세스는 잠을 잔다.

- 프로세스는 생성(new) 이후 종료(terminated) 전까지 준비(ready)와 실행(running)과 대기(waiting) 상태를 반복한다.
- 이러한 매커니즘은 하나의 프로세스만 CPU를 사용할 수 있기 때문에 필요하다.
- DB 프로세스도 디스크에서 데이터를 읽어야 할 땐(디스크 I/O) CPU를 OS에 반환하고 waiting 상태에서 대기한다. 그러므로 일해야 할 프로세스가 대기를 하고 있으니 I/O가 많으면 DB 성능이 떨어진다.
2. 데이터베이스 저장 구조
- 데이터베이스를 논리적 구조로 보면 테이블스페이스 - 세그먼트 - 엑스텐트 - 블록(오라클)로 가면서 작은 단위가 된다.
- 테이블 스페이스는 논리적으로는 세그먼트를 담는 컨테이너이면서 물리적으로는 여러 데이터 파일(물리적인 OS 파일)로 구성되어 있다.
- 세그먼트는 테이블, 인덱스와 같은 데이터 저장공간이 필요한 데이터베이스 오브젝트이다.
- 익스텐트는 공간을 확장하는 단위이다. 테이블이나 인덱스에, 즉 세그먼트에 데이터를 넣을 공간이 부족해지면 테이블스페이스로부터 추가 할당을 받는다.
- 익스텐트는 연속된 블록들의 집합이다. 블록은 DBMS가 데이터를 읽고 쓰는 단위이다.
- 익스텐트 단위로 공간을 확장하지만 데이터를 저장하는 공간은 데이터 블록이다.
- 익스텐트 내의 블록은 데이터 파일 안에 연속적으로 저장되어 있지만 익스텐트끼리는 분산되어 있다.
3. 시퀀셜 엑세스
- Sequential 엑세스는 논리적 또는 물리적으로 연결된 순서에 따라 차례대로 블록을 읽는 방식
- 인덱스 리프 블록은 앞뒤를 가리키는 주소값을 통해 논리적으로 서로 연결되어 있음
- 이 주소값에 따라 앞 또는 뒤로 순차적으로 스캔하는 방식을 스퀀셜 엑세스라고 한다.
- 테이블의 경우 인덱스와 달리 논리적인 연결고리(리프 블록의 주소값)가 없다. 오라클은 세그먼트에 할당된 익스텐트 목록을 헤더에 MAP으로 관리한다. 이 정보를 가지고 순서대로 읽어나가는 것이 TABLE FULL SCAN이다.
4. 랜덤 엑세스
- Random 엑세스는 논리적, 물리적 순서를 따르지 않고 레코드 하나를 읽기 위해 한 블록씩 접근하는 방식이다.
- 나중에 제대로 알아보자
5. 논리적 I/O vs 물리적 I/O
- 데이터베이스 버퍼 캐시는 데이터를 캐싱하는 공간이다. 데이터 캐시로서 데이터 블록을 캐싱해 둠으로써 같은 블록에 대한 반복적인 I/O를 줄이는 데 사용된다.
- 서버 프로세스와 데이터파일 사이에 버퍼 캐시가 있으므로 데이터 블록을 읽을 땐 항상 먼저 버퍼캐시를 탐색한다. 버퍼 캐시에 찾고자 하는 데이터가 있다면 디스크에 다녀올 필요가 없어진다.
- 논리적 I/O는 SQL 처리과정에서 발생한 총 블록 I/O를 말한다. 즉 디스크에 물리적으로 접근하냐 하지 않느냐가 아니라 버퍼 캐시를 지나는 I/O 모두가 논리적 I/O이다.
- 물리적 I/O는 디스크에 접근한 I/O를 말한다. 버퍼 캐시에서 원하는 데이터를 찾지 못하면 디스크에 물리적으로 접근하게 된다. 이를 물리적 I/O라고 한다.
6. 버퍼캐시 히트율 (BCHR)
- Buffer Cache Hit Ratio = (캐시에서 바로 찾은 블록 수 / 총 읽은 블록 수)
= (논리적 I/O - 물리적 I/O) / 논리적 I/O) = (1 - 물리적 I/O) / 논리적 I/O
- 위 공식을 보면 히트율을 높이기 위해선 논리적 I/O를 줄여야 한다. 물리적 I/O는 시스템 상황에 비해 결정되는 통제 불가능한 외생변수이므로 논리적 I/O를 줄여 성능을 높여야 한다.
- 논리적 I/O를 줄이는 방법은 읽는 총 블록 개수를 줄이는 것이다.
- 논리적 I/O를 줄여 물리적 I/O를 줄이는 것이 곧 SQL 튜닝이다.
7. Single Block I/O vs Multiblock I/O
- 싱글 블록 I/O : 한 번에 한 블록씩 요청해서 메모리에 적재
- 멀티 블록 I/O : 한 번에 여러 블록 요청해서 메모리에 적재
- 인덱스를 이용할 때는 기본적으로 인덱스와 테이블 모두 Single Block 방식 사용
- 인덱스 루트 블록 읽을 때
- 인덱스 루트 블록에서 얻은 주소 정보로 브랜치 블록을 읽을 때
- 인덱스 브랜치 블록에서 얻은 주소 정보로 리프 블록을 읽을 때
- 인덱스 리프 블록에서 얻은 주소 정보로 테이블 블록을 읽을 때
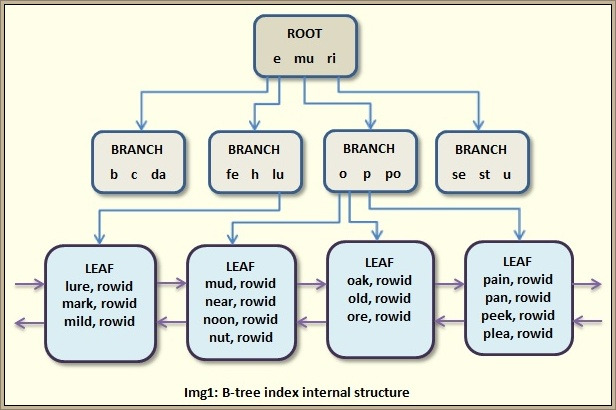
- 그림과 같은 블록들을 읽을 때 사용한다.
- 많은 테이블 블록을 읽을 때는 Multiblock 방식이 효율적이다. 테이블 전체를 스캔할 때도 이 방식을 사용한다.
8. Table Full Scan vs. Index Range Scan
- Table Full Scan은 말 그대로 테이블에 속한 전체 블록을 읽어서 사용자가 원하는 데이터를 찾는 방식
- 인덱스를 이용한 방식은 인덱스에서 일정량 스캔하면서 얻은 ROWID로 테이블 레코드를 찾아가는 방식
- ROWID는 테이블 레코드가 디스크 상에 어디 저장되어있는지를 가리키는 위치 정보
- Index Range Scan은 랜덤 엑세스와 Single Block I/O 방식으로 디스크 블록을 읽는다. 캐시에서 블록을 못찾으면 레코드 하나를 읽으려고 매번 잠을 자는 매커니즘이다. 따라서 많은 데이터를 읽을 때는 Table Full Scan보다 불리하다.
- 자세한 Index 작동 방식은 다음 글부터 공부한다.
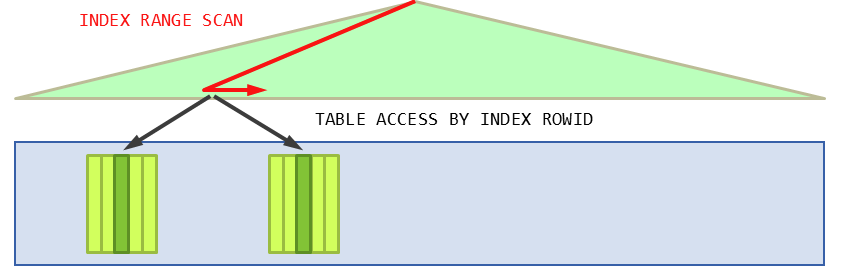
- 데이터가 일정량을 넘어가면 Table Full Scan이 인덱스를 활용하는 것보다 좋을 수 있다.
9. 메모리 공유자원에 대한 엑세스 직렬화
- 공유 캐시의 특정 자원을 두 개 이상의 프로세스가 같이 사용할 수 없다. 특정 순간에는 한 프로세스만 사용 가능하다.
- 프로세스는 줄을 서서 대기해야 한다(직렬화). 이를 가능케 하는 매커니즘이 Latch이다.
- 버퍼 캐시에는 캐시 버퍼 체인 래치, 캐시버퍼 LRU 체인 래치 등이 작동한다.
- 이 외에도 버퍼 블록 자체에도 버퍼 Lock이라는 직렬화 매커니즘이 존재한다.
'OLD' 카테고리의 다른 글
| 개인 블로그 프로젝트 - 1. 어떤 기능을 만들까? (8) | 2024.10.09 |
|---|---|
| SQLP 기초 - 3. 인덱스 구조 및 탐색 (1) | 2024.10.09 |
| SQLP 기초 - 1. SQL 처리 과정 : 파싱, 최적화, 캐싱 (0) | 2024.10.07 |
| (작업중)SSL이란 (with SAP) (1) | 2024.06.11 |
| (작업중)EASY ABAP - 11. Report Program (With ALV) (0) | 2024.06.10 |