sqld-2
SQL 기본
관계형 데이터베이스
- 계층형 데이터베이스
- 네트워크형 데이터베이스
- 관계형 데이터베이스
- 집합연산
- 합집함
- 차집함
- 교집합
- 곱집합
- 관계연산
- 선택연산
- 투영연산
- 결합연산
- 나누기연산
- 테이블 구조
- 릴레이션 → 테이블
- 기본키 : unique, 최소성, not null
- 행 = 튜플
- 컬럼 = 필드 = 속성
- 외래키 : 다른 테이블의 기본키 참조
- SQL 종류
- DDL
- DML
- DCL
- TCL
- 트랜잭션 : 트랜잭션은 데이터베이스의 작업을 처리하는 단위
- 트랜잭션의 특성
- 원자성(Atomicity) : 트랜잭션은 연산의 전부가 실행되거나 전혀 실행되지 않아야 한다(all or nothing)
- 일관성(Consistency) : 트랜잭션 실행 결과로 데이터베이스의 상태가 모순되지 않아야 한다.
- 고립성(Isolation) : 트랜잭션 실행 중에 연산의 중간결과는 다른 트랜잭션이 접근할 수 없다.
- 영속성(Durability) : 트랜잭션이 성공적으로 실행되면 그 결과는 영구적으로 보장되어야 한다.
- 트랜잭션의 특성
- SQL 실행 순서
- 파싱(Parsing) : 문법을 확인하고 구문 분석
- 실행(Execution) : 옵티마이저가 수립한 실행 계획에 따라 SQL 실행
- 인출(Fetch) : 데이터 읽어서 전송
DDL
CREATE TABLE DEPT(
deptno varchar2(4) primary key
, deptname varchar2(20)
);
CREATE TABLE EMP (
empno number(10)
, ename varchar2(20)
, sal number(10,2) default 0
, deptno varchar2(4) not null
, createdate date default sysdate
, constraint emppk primary key(empno)
, constraint deptfk foreign key(deptno) references dept(deptno) ON DELETE CASCADE -- 자동으로 자신도 삭제
);ALTER TABLE EMP RENAME TO NEW_EMP;
ALTER TABLE EMP ADD (age number(2) default 1);
ALTER TABLE EMP MODIFY (ename varchar2(40) not null); -- 컬럼 변경
ALTER TABLE EMP DROP COLUMN age;
ALTER TABLE EMP RENAME COLUMN ename TO new_ename; -- 컬럼명 변경
ALTER TABLE EMP
ADD CONSTRAINT EMPNO_PK PRIMARY KEY (EMPNO);DROP TABLE EMP;
DROP TABLE EMP CASCADE CONSTRAINT; -- 해당 테이블의 데이터를 외래키로 참조한 슬레이브 테이블과 관련된 제약사항도 삭제
-- 외래키(Foreign key)로 물린 하위 테이블들 까지 함께 삭제된다. DEPT 삭제 시 EMP 도 삭제된다는 뜻VIEW
- 테이블로부터 유도된 가상의 테이블
- 데이터 딕셔너리에 SQL문 형태로 저장하되 실행 시에 참조된다
- 특징
- 참조한 테이블이 변경되면 뷰도 변경
- 뷰에 대한 입력 수정 삭제에는 제약 있음
- 특정 컬럼만 조회시켜 보안을 향상
- 한번 생성된 뷰는 변경 불가 → 삭제하고 재생성해야 한다(ALTER 불가)
CREATE VIEW T_EMP AS
SELECT * FROM EMP;
DROP VIEW T_EMP;- 뷰의 장단점
- 장점
- 특정 컬럼만 조회 → 보안성 향상
- 데이터 관리가 간단
- select 문이 간단해짐
- 하나의 테이블에 대해 여러 개의 뷰 생성 가능
- 단점
- 독자적인 인덱스를 만들 수 없음
- 삽입 수정 삭제가 제한
- 데이터 구조를 변경할 수 없음
- 장점
DML
- INSERT
INSERT INTO EMP(EMPNO, ENAME) VALUES(1000, 'TOTO');
INSERT INTO DEPT2
SELECT *
FROM DEPT;
set autocommit on;
set autocommit off;
show autocommit;
ALTER TABLE DEPT NOLOGGING;- Nologging
- Nologging 옵션은 로그파일의 기록을 최소화 → 입력 성능 향상
- Buffer Cache라는 메모리 영역을 생략하고 기록한다.
- UPDATE
UPDATE EMP
SET ENAME = 'TOTO'
WHERE EMPNO = 100;- DELETE
DELETE FROM EMP
WHERE EMPNO =100;- 테이블 용량이 초과되지 않는다?
- 테이블에 데이터가 입력되면 Extent에 저장된다
- 만약 Extent의 크기가 MAX_EXTENTS를 넘어가면 용량 초과 오류 발생 → 최대로 저장할 수 있는 공간의 의미
- DELETE문으로 데이터를 삭제하면 용량이 감소하지 않고 삭제 여부만 표시하고 용량은 초기화되지 않는다.
- Data Dictionary에서 테이블 정보 조회 가능
SELECT TABLE_NAME , MAX_EXTENTS FROM USER_TABLES
- → Oracle 데이터베이스는 저장공간을 할당할 때 Extent 단위로 할당한다.
- 테이블의 모든 데이터 삭제
DELETE FROM TBL; -- 모든 데이터 삭제, 용량 감소 X
TRUNCATE TABLE TBL; -- 모든 데이터 삭제, 용량 감소 O인덱스
- Oracle 데이터베이스는 정렬을 위해 메모리 내부에 할당된 SORT_AREA_SIZE를 사용 → 너무 작으면 성능 저하 발생
- 정렬을 회피하기 위해 INDEX를 생성할 때 사용자가 원하는 형태로 오름차순 혹은 내림차순으로 생성해야 한다.
- 정렬은 부하를 주므로 인덱스를 사용해 ORDER BY를 회피할 수 있다.
-- 힌트 사용
SELECT /*+ INDEX_DESC(A) */ * -- 내림차순
FROM EMP A;
-- index_asc, index 힌트 : 인덱스 영역에서 순방향으로 스캔 하라는 뜻
SELECT /*+ index_asc(e idx_myemp1_ename) */
EMPNO, ENAME, SAL FROM MYEMP1 e
WHERE ENAME >= '가'WHERE
- 부정비교 연산자
- != : 같지 않은 것을 조회
- ^= : 같지 않은 것을 조회
- <> : 같지 않은 것을 조회
- NOT 컬럼명 = : 같지 않은 것을 조회
- NOT 컬럼명 > : 크지 않은 것을 조회
- 논리연산자
- AND
- OR
- NOT
- SQL 연산자
- LIKE ‘%문자열%’
- BETWEEN A AND B : A이상 B이하
- NOT BETWEEN A AND B : A미만 B초과
-- IN 사용법
SELECT *
FROM EMP
WHERE (JOB, SAL) IN
(
('CLERK', 800)
, ('CLERK', 1300)
)
;- NULL
- 모르는 값
- 값의 부재
- NULL 과 숫자 혹은 날짜를 더하면 NULL
- NULL과 어떤 값을 비교하면 ‘알 수 없음’ 반환
- IS NULL, IS NOT NULL 사용
- NULL 관련 함수
- NVL : NULL 값을 다른 값으로 대체
- 사용 방법 : NVL(컬럼명, 대체할 값)
- 예시 : SELECT NVL(job, 'Unknown') FROM emp;
- NVL2 : NULL 값일 경우와 NULL이 아닐 경우에 따라 다른 값을 반환
- 사용 방법 : NVL2(컬럼명, NULL이 아닐 경우 반환할 값, NULL일 경우 반환할 값)
- 예시 : SELECT NVL2(job, 'Job exists', 'No job exists') FROM emp;
- NULLIF : 두 값이 같으면 NULL 반환, 다르면 첫 번째 값 반환
- 사용 방법 : NULLIF(비교할 값1, 비교할 값2)
- 예시 : SELECT NULLIF(job, 'CLERK') FROM emp;
- COALESCE : NULL이 아닌 첫 번째 값을 반환, 모두 NULL이면 NULL 반환
- 사용 방법 : COALESCE(컬럼명1, 컬럼명2, ..., 컬럼명n)
- 예시 : SELECT COALESCE(job, ename, 'Unknown') FROM emp;
- NVL : NULL 값을 다른 값으로 대체
GROUP BY
- 집계 함수 종류
- COUNT()
- SUM()
- AVG()
- MAX(), MIN()
- STDDEV()
- VARIAN()
SELECT deptno, COUNT(*) AS count FROM emp GROUP BY deptno; SELECT deptno, SUM(sal) AS total_salary FROM emp GROUP BY deptno; SELECT deptno, AVG(sal) AS average_salary FROM emp GROUP BY deptno; SELECT deptno, MAX(sal) AS max_salary, MIN(sal) AS min_salary FROM emp GROUP BY deptno; SELECT deptno, STDDEV(sal) AS salary_stddev FROM emp GROUP BY deptno; SELECT deptno, VARIANCE(sal) AS salary_variance FROM emp GROUP BY deptno;- 다음은 GROUP BY를 사용하여 위 함수들의 예시
- SELECT 문 실행 순서
- FROM → WHERE → GROUP BY → HAVING → SELECT → ORDER BY
형변환
데이터 타입이 서로 다른 컬럼간의 연산 예시
문자열과 숫자를 더하는 쿼리
SELECT '100' + 200 FROM dual;위 쿼리는 ORACLE DATABASE에서 에러가 발생합니다.
따라서, TO_CHAR 혹은 TO_NUMBER 함수를 이용하여 데이터 타입을 변환하여야 합니다.
-- TO_CHAR 함수를 이용한 문자열과 숫자를 더하는 쿼리
SELECT TO_CHAR(100) || 200 FROM dual;
-- TO_NUMBER 함수를 이용한 문자열과 숫자를 더하는 쿼리
SELECT TO_NUMBER('100') + 200 FROM dual;날짜 비교를 위한 암시적 형변환 예시
SELECT *
FROM emp
WHERE hiredate >= '01-JAN-90';- 인덱스 칼럼에 형변환을 수행하면 인덱스를 사용하지 못한다
- 명시적 형변환으로 해결한다.
- EX) WHERE EMPNO = TO_NUMBER(’100’)
내장형 함수
ORACLE의 내장형 함수 중 문자열 함수는 다음과 같습니다.
- CONCAT() : 문자열을 합칩니다.
SELECT CONCAT('Hello', ' World') FROM dual;- LENGTH() : 문자열의 길이를 반환합니다.
SELECT LENGTH('Hello World') FROM dual;- UPPER() : 문자열을 대문자로 변환합니다.
SELECT UPPER('hello world') FROM dual;- LOWER() : 문자열을 소문자로 변환합니다.
SELECT LOWER('HELLO WORLD') FROM dual;- TRIM() : 문자열의 양쪽 끝에서 공백을 제거합니다.
SELECT TRIM(' Hello World ') FROM dual;- SUBSTR() : 문자열의 일부를 반환합니다. 첫 번째 매개변수는 문자열이고, 두 번째 매개변수는 시작 위치, 세 번째 매개변수는 반환할 문자열의 길이입니다.
SELECT SUBSTR('Hello World', 7, 5) FROM dual;- INSTR() : 문자열에서 첫 번째로 나타나는 문자열의 위치를 반환합니다. 첫 번째 매개변수는 대상 문자열, 두 번째 매개변수는 찾을 문자열입니다.
SELECT INSTR('Hello World', 'Wo') FROM dual;- REPLACE() : 문자열에서 특정 문자열을 대체합니다. 첫 번째 매개변수는 대상 문자열, 두 번째 매개변수는 변경할 문자열, 세 번째 매개변수는 대체될 문자열입니다.
SELECT REPLACE('Hello World', 'Hello', 'Hi') FROM dual;- ASCII() : 문자의 아스키 코드 값을 반환합니다.
SELECT ASCII('A') FROM dual;- CHAR() : 아스키 코드 값을 문자로 변환합니다.
SELECT CHR(65) FROM dual;SELECT SYSDATE
, EXTRACT(YEAR FROM SYSDATE) AS YEAR
, EXTRACT(MONTH FROM SYSDATE) AS MONTH
, EXTRACT(DAY FROM SYSDATE) AS DAY
FROM DUAL
;- ABS() : 절대값을 반환합니다.
SELECT ABS(-100) FROM dual;- CEIL() : 인수보다 크거나 같은 최소 정수를 반환합니다.
SELECT CEIL(3.14) FROM dual;- FLOOR() : 인수보다 작거나 같은 최대 정수를 반환합니다.
SELECT FLOOR(3.14) FROM dual;- MOD() : 나머지를 반환합니다.
SELECT MOD(10, 3) FROM dual;- POWER() : 제곱 값을 반환합니다.
SELECT POWER(2, 3) FROM dual;- ROUND() : 인수를 반올림합니다. 두 번째 매개변수를 사용하여 소수점 이하 자리 수를 지정할 수 있습니다.
SELECT ROUND(3.141592, 2) FROM dual;- SIGN() : 인수의 부호를 반환합니다.
SELECT SIGN(-100) FROM dual;- SQRT() : 제곱근 값을 반환합니다.
SELECT SQRT(16) FROM dual;- TRUNC() : 인수에서 소수점 이하를 제거합니다. 두 번째 매개변수를 사용하여 자리 수를 지정할 수 있습니다.
SELECT TRUNC(3.141592, 2) FROM dual;DECODE AND CASE
DECODE
DECODE 함수는 값에 따라 다른 값을 반환합니다. 다음은 DECODE 함수의 구조입니다.
DECODE(expression, search1, result1, search2, result2, ..., default)- expression : 비교할 값
- search1, search2, ... : 비교할 값의 목록
- result1, result2, ... : search에 일치할 때 반환할 값
- default : search와 일치하는 값이 없을 때 반환할 값
DECODE 함수는 가독성이 떨어지므로, CASE 함수를 사용하는 것을 권장합니다.
CASE
CASE 함수는 DECODE 함수와 유사하지만, 더 다양한 조건을 처리할 수 있습니다. 다음은 CASE 함수의 구조입니다.
CASE
WHEN condition1 THEN result1
WHEN condition2 THEN result2
...
ELSE default
END- condition1, condition2, ... : 비교할 조건
- result1, result2, ... : 조건에 일치할 때 반환할 값
- default : 모든 조건과 일치하지 않을 때 반환할 값
CASE 함수는 다음과 같은 방식으로 사용할 수 있습니다.
SELECT
CASE
WHEN job = 'MANAGER' THEN 'Manager'
WHEN job = 'CLERK' THEN 'Clerk'
ELSE 'Other'
END AS job_title
FROM emp;
SELECT ENAME, JOB, SAL,
CASE JOB
WHEN 'MANAGER' THEN SAL * 1.2
WHEN 'SALESMAN' THEN SAL * 1.1
ELSE SAL
END AS "Adjusted Salary"
FROM EMP;위 쿼리는 job 컬럼의 값이 'MANAGER'일 경우 'Manager', 'CLERK'일 경우 'Clerk', 그 외의 경우 'Other'를 반환합니다.
- ROWNUM: 쿼리 결과 집합에서 반환되는 각 행의 고유 번호입니다. 즉, SELECT 문이 반환하는 결과 집합에서 각 행의 번호를 매기는 열입니다.
- ROWID: 테이블에서 각 행을 고유하게 식별할 수 있는 식별자입니다. 이 값은 해당 행의 저장 위치를 나타내는 값으로, ROWID 값을 사용하여 테이블에서 특정 행을 참조할 수 있습니다.
SELECT ROWNUM AS "Row Number", ENAME, JOB, SAL
FROM EMP
WHERE ROWNUM <= 3;
SELECT ROWID, ROWNUM AS "Row Number", ENAME, JOB, SAL
FROM EMP
WHERE ROWID = 'AAAHQJAAEAAAB4vAAA';
/*
데이터 파일 번호: 'AAA' (10진수로 0)
블록 번호: 'HQJ' (10진수로 2891)
블록 내 위치: 'AAA' (10진수로 0)
행 번호: 'B4v' (16진수로 AA B4v를 10진수로 변환하면 4703)
즉, 이 ROWID 값은 데이터 파일 0의 2891번 블록 내의 4703번 행을 식별합니다.
첫 번째 AAA는 데이터 파일 번호를 나타내며,
두 번째 AAA는 블록 내에서의 행의 위치를 나타내는 것입니다.
마지막 AAA는 데이터 파일 내에서 블록의 위치를 나타낸다.
*/-- SQL Server
SELECT TOP(10) FROM EMP; -- 10명만 FETCH
-- MySQL
SELECT * FROM EMP LIMIT 10;- WITH 구문
WITH VIEWDATA AS
( SELECT * FROM EMP
UNION ALL
SELECT * FROM EMP
)
SELECT * FROM VIEWDATA WHERE EMPNO = '7369'
;DCL
- GRANT
GRANT privileges ON object TO user;
GRANT SELECT ON employees TO user1;
GRANT INSERT ON employees TO user2;
GRANT UPDATE ON employees.salary TO user3; -- 특정 컬럼만 UPDATE 가능
GRANT DELETE ON employees TO user4;
GRANT REFERENCES ON departments(dept_id) TO user5;
-- REFERENCES 권한은 외래 키 제약 조건을 설정하는 데 사용
GRANT EXECUTE ON stored_proc TO user6;
-- 'stored_proc' 저장 프로시저에 대해 EXECUTE 권한을 'user6' 사용자에게 부여함
-- EXECUTE 권한은 저장 프로시저, 함수, 프로시저 등을 실행하는 데 사용- WITH GRANT OPTION
- 특정 사용자에게 권한을 부여할 수 있는 권한 부여
- 부여자에 대한 권한을 회수하면 부여자가 부여한 권한을 가진 유저에게서도 권한을 회수한다.
- WITH ADMIN OPTION
- 테이블에 대한 모든 권한 부여
- 부여자에 대한 권한을 회수하면 부여자에 대한 권한만 회수한다.
GRANT SELECT, INSERT, UPDATE, DELETE ON EMP TO USER1 WITH GRANT OPTION;REVOKE privileges ON object FROM user2;TCL
- COMMIT은 INSERT, UPDATE, DELETE문으로 변경한 데이터를 데이터베이스에 반영한다.
- COMMIT이 완료되면 데이터베이스 변경으로 인한 LOCK이 해제된다(UNLOCK)
- COMMIT이 완료되면 다른 모든 데이터베이스 사용자는 변경된 데이터를 조작할 수 있다.
- COMMIT을 실행하면 하나의 트랜잭션 과정을 종료한다.
- ROLLBACK을 실행하면 데이터에 대한 변경 사용을 모두 취소하고 트랜잭션을 종료한다.
- 이전에 COMMIT한 곳까지만 복구한다
- ROLLBACK을 실핸한 후 LOCK이 해제된다
- SAVEPOINT은 트랜잭션을 작게 분할하여 관리하는 것
- ROLLBACK TO SAVEPOINT명;
BEGIN TRANSACTION;
INSERT INTO employees (id, name, age, department) VALUES (1, 'John Doe', 30, 'Sales');
SAVEPOINT before_update;
UPDATE employees SET age = 35 WHERE id = 1;
INSERT INTO employee_sales (id, amount) VALUES (1, 10000);
-- 에러가 발생하여 롤백을 해야 할 때
ROLLBACK TO before_update;
COMMIT;SQL 활용
JOIN
SELECT *
FROM EMP, DEPT
WHERE EMP.DEPTNO = DEPT.DEPTNO (+)
;
SELECT *
FROM EMP
LEFT OUTER JOIN DEPT ON EMP.DEPTNO = DEPT.DEPTNO
;
SELECT *
FROM EMP
RIGHT OUTER JOIN DEPT ON EMP.DEPTNO = DEPT.DEPTNO
;
SELECT *
FROM EMP, DEPT
WHERE EMP.DEPTNO (+) = DEPT.DEPTNO
;
-- 교집합
SELECT DEPTNO FROM EMP
INTERSECT
SELECT DEPTNO FROM DEPT
;UNION
- UNION ALL은 정렬은 유발하지 않는다.
- MINUS 연산은 차집합 조회
- MS-SQL에서는 MINUS와 동일한 연산이 EXCEPT이다
SELECT DEPTNO FROM DEPT
MINUS
SELECT DEPTNO FROM EMP
;CONNECT BY
CONNECT BY를 사용하면, 각 노드와 부모 노드 간의 관계를 사용하여 계층 구조를 생성하고 순회할 수 있습니다.
이를 위해서는, 일반적으로 CONNECT BY 조건에 부모와 자식 노드 간의 관계를 나타내는 조인 조건을 지정해주어야 합니다.
SELECT EMP.EMPNO, EMP.ENAME, EMP.MGR, LEVEL
FROM EMP
CONNECT BY PRIOR EMP.EMPNO = EMP.MGR -- PRIOR 키워드는 이전 행을 의미한다. 부모 노드의 EMPNO가 나의 MGR인 것을 찾음
START WITH EMP.MGR IS NULL -- MGR이 NULL인 곳에서 시작
ORDER BY LEVEL; | EMPNO | ENAME | MGR | LEVEL |
|---|---|---|---|
| 7839 | KING | NULL | 1 |
| 7566 | JONES | 7839 | 2 |
| 7698 | BLAKE | 7839 | 2 |
| 7782 | CLARK | 7839 | 2 |
| 7902 | FORD | 7566 | 3 |
| 7521 | WARD | 7698 | 3 |
| 7900 | JAMES | 7698 | 3 |
| 7934 | MILLER | 7782 | 3 |
| 7499 | ALLEN | 7698 | 3 |
| 7788 | SCOTT | 7566 | 3 |
| 7654 | MARTIN | 7698 | 3 |
| 7844 | TURNER | 7698 | 3 |
| 7876 | ADAMS | 7788 | 4 |
| 7369 | SMITH | 7902 | 4 |
- CONNECT BY 키워드
| LEVEL | 검색 항목의 깊이 |
|---|---|
| CONNECT_BY_ROOT | 계층 구조에서 최상위 |
| CONNECT_BY_ISLEAF | 계층 구조에서 가장 최하위이면 1 아니면 0 |
| SYS_CONNET_BY_PATH | 계층 구조의 전체 전개 경로 |
| NOCYCLE | 순환 구조가 발생지점까지만 전개 |
| CONNECT_BY_ISCYCLE | 순환 구조 발생 지점을 표시 |
SELECT empno, ename, job, mgr, LEVEL,
SYS_CONNECT_BY_PATH(ename, '/') AS path
FROM emp
CONNECT BY PRIOR empno = mgr
START WITH mgr IS NULL;| EMPNO | ENAME | JOB | MGR | LEVEL | PATH |
|---|---|---|---|---|---|
| 7839 | KING | PRESIDENT | 1 | /KING | |
| 7566 | JONES | MANAGER | 7839 | 2 | /KING/JONES |
| 7788 | SCOTT | ANALYST | 7566 | 3 | /KING/JONES/SCOTT |
| 7876 | ADAMS | CLERK | 7788 | 4 | /KING/JONES/SCOTT/ADAMS |
| 7902 | FORD | ANALYST | 7566 | 3 | /KING/JONES/FORD |
| 7369 | SMITH | CLERK | 7902 | 4 | /KING/JONES/FORD/SMITH |
| 7698 | BLAKE | MANAGER | 7839 | 2 | /KING/BLAKE |
| 7499 | ALLEN | SALESMAN | 7698 | 3 | /KING/BLAKE/ALLEN |
| 7521 | WARD | SALESMAN | 7698 | 3 | /KING/BLAKE/WARD |
| 7654 | MARTIN | SALESMAN | 7698 | 3 | /KING/BLAKE/MARTIN |
| 7844 | TURNER | SALESMAN | 7698 | 3 | /KING/BLAKE/TURNER |
| 7900 | JAMES | CLERK | 7698 | 3 | /KING/BLAKE/JAMES |
| 7782 | CLARK | MANAGER | 7839 | 2 | /KING/CLARK |
| 7934 | MILLER | CLERK | 7782 | 3 | /KING/CLARK/MILLER |
Subquery
- FROM구에 SELECT문을 사용하면 Inline View
- SELECT구에 서브쿼리를 사용하면 Scala Subquery라고 한다
- WHERE구에 SELECT문을 사용하면 Subquery 라고 한다.( 밖에 있는 SELECT는 Main query)
SELECT *
FROM EMP
WHERE SAL > ANY (SELECT AVG(SAL) FROM EMP GROUP BY DEPTNO);
-- 부서별 평균 급여 중 가장 작은 것 보다 크면 출력됨
SELECT *
FROM EMP
WHERE SAL > ALL (SELECT AVG(SAL) FROM EMP GROUP BY DEPTNO);
-- 가장 큰 것보다 커야함
SELECT *
FROM EMP
WHERE EXISTS (SELECT 1 FROM DEPT WHERE DEPTNO = EMP.DEPTNO AND LOC = 'NEW YORK');
-- DEPTNO = EMP.DEPTNO인 직원의 부서가 NEW YORK에 위치하면 출력.. -> 즉, NEW YORK에 부서가 위치한 사람만 출력- ROLLUP을 사용하면 GROUP BY 절에서 지정한 컬럼을 기준으로 서브 토탈을 계산하고 전체 토탈까지 계산
SELECT DECODE(GROUPING(dname), 1, 'ALL', dname) dname,
DECODE(GROUPING(job), 1, 'ALL', job) job,
COUNT(*) cnt
FROM emp e, dept d
WHERE e.deptno = d.deptno
GROUP BY ROLLUP(dname, job);- GROUPING은 GROUP BY 구문에서 사용되는 집계 함수 중 하나로, 데이터를 그룹화하여 집계를 수행할 때 NULL 값을 가지는 데이터를 대표하는 값을 반환
- GROUPING SETS는 GROUP BY를 사용하여 그룹화할 컬럼들의 집합을 나타냅니다.
위의 예시에서는 deptno와 job으로 묶인 그룹, deptno로 묶인 그룹, 전체 데이터에 대한 그룹을 나타내는 3개의 그룹으로 나누어 집계를 수행
SELECT deptno, job, SUM(sal)
FROM emp
GROUP BY GROUPING SETS ((deptno, job), (deptno), ())
ORDER BY deptno, job NULLS FIRST;
SELECT deptno, job, SUM(sal), GROUPING(deptno), GROUPING(job)
FROM emp
GROUP BY GROUPING SETS ((deptno, job), (deptno), ())
ORDER BY deptno, job;- CUBE : CUBE는 GROUP BY 절에서 집계 함수를 사용할 때, 지정된 열에 대해 가능한 모든 조합을 대상으로 집계를 수행하는 기능
SELECT Region, Product, SUM(Sales)
FROM Sales
GROUP BY CUBE(Region, Product)
ORDER BY Region NULLS LAST,Product NULLS LAST;| REGION | PRODUCT | SUM(SALES) |
|---|---|---|
| EAST | A | 100 |
| EAST | B | 200 |
| EAST | 300 | |
| WEST | A | 150 |
| WEST | B | 250 |
| WEST | NULL | 400 |
| NULL | A | 250 |
| NULL | B | 450 |
| NULL | NULL | 700 |
Window Function
SELECT WINDOW_FUNCTION(ARGUMENTS)
OVER (PARTITION BY COLUMN ORDER BY WINDOWING절)
FROM TBL_NAME
;- 윈도우 함수 구조
| 구조 | 설명 |
|---|---|
| ARGUMENTS | 윈도우 함수에 따라서 인수 설정 |
| PARTITION BY | 전체 집합을 기준에 의해 소그룹 |
| ORDER BY | 어떤 항목에 대해 정렬 |
| WINDOWING절 | 행 기준의 범위를 정한다. |
| ROWS는 물리적 결과의 행 수 | |
| RANGE는 논리적인 값에 의한 범위이다. | |
| - WINDOWING |
| 구조 | 설명 |
|---|---|
| ROWS BETWEEN | 행을 기준으로 어느 범위까지 함수를 적용할지 설정 |
| RANGE BETWEEN | 데이터의 순서를 기준으로 어느 범위까지 함수를 적용할지 설정 |
| UNBOUNDED PRECEDING/FOLLOWING | 해당 창의 시작점이나 끝점까지 함수를 적용 |
| CURRENT ROW | 현재 처리 중인 행에 대해서만 함수를 적용 |
-- 전체 행
SELECT EMPNO, ENAME, SAL
, SUM(SAL) OVER(ORDER BY SAL ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) TOTAL_SAL
FROM EMP
;
-- 현재까지의 합(누적 합계)
SELECT EMPNO, ENAME, SAL
, SUM(SAL) OVER(ORDER BY SAL ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) TOTAL_SAL
FROM EMP
;RANK Function
SELECT ENAME, JOB, SAL
, RANK() OVER (ORDER BY SAL DESC) ALL_RANK
, DENSE_RANK() OVER (ORDER BY SAL DESC) ALL_DENSE_RANK
, ROW_NUMBER() OVER (ORDER BY SAL DESC) ROW_NUM
, RANK() OVER (PARTITION BY JOB ORDER BY SAL DESC) JOB_RANK
FROM EMP- DENSE_RANK 는 동일한 순위를 하나의 건수로 계산
- ROW_NUMBER는 동일한 순위에 대해서 고유의 순위 부여
- AGGREGATE Function
SELECT ENAME, JOB, SAL
, SUM(SAL) OVER (PARTITION BY JOB) SUM_JOB
, ROUND(AVG(SAL) OVER (PARTITION BY JOB),2) AVG_JOB
, COUNT(SAL) OVER (PARTITION BY JOB) COUNT_JOB
, MAX(SAL) OVER (PARTITION BY JOB) MAX_JOB
, MIN(SAL) OVER (PARTITION BY JOB) MIN_JOB
FROM EMP
;- 행 순서 관련 함수
SELECT DEPTNO, ENAME, SAL
, FIRST_VALUE(ENAME) OVER (PARTITION BY DEPTNO
ORDER BY SAL DESC
ROWS UNBOUNDED PRECEDING) AS DEPT_TOP
, LAST_VALUE(ENAME) OVER (PARTITION BY DEPTNO
ORDER BY SAL DESC
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS DEPT_LOWEST
FROM EMP
;
SELECT DEPTNO, ENAME, SAL
, LAG(SAL) OVER(ORDER BY SAL DESC) AS PRE_SAL
, LEAD(SAL, 2) OVER(ORDER BY SAL DESC) AS PRE_SAL_2 -- 다음 2번째
FROM EMP;- 비율 관련 함수
SELECT DEPTNO, ENAME, SAL
, PERCENT_RANK() OVER(PARTITION BY DEPTNO ORDER BY SAL DESC) AS PERCENT_SAL -- 순위가 차지하는 퍼센트
, NTILE(5) OVER(PARTITION BY DEPTNO ORDER BY SAL DESC) AS N_TILE -- 5개의 그룹으로 나눈 분포
, CUME_DIST() OVER(PARTITION BY DEPTNO ORDER BY SAL DESC) AS CUME_DIST -- 누적 퍼센트
, RATIO_TO_REPORT(SAL) OVER(PARTITION BY DEPTNO) AS RATIO_TO_REPORT -- SUM에서 차지하는 퍼센트
FROM EMP
;테이블 파티션
- Partition 기능
- 대용량의 테이블을 여러 개의 데이터 파일에 분리해서 저장
- Range Partition
- 테이블의 칼럼 중에서 값의 범위를 기준으로 여러 개의 파티션으로 데이터를 나누어 저장하는 것
- List Partition
- 특정 값을 기준으로 분할
- Hash Partition
- 내부적으로 해시 함수를 사용해서 데이터를 분할, DBMS가 알아서 한다.
- Composite Partition은 여러 개의 파티션 기법을 조합해서 사용
- Partition Index
- Global Index : 여러 개의 파티션에서 하나의 인덱스를 사용
- Local Index : 해당 파티션 별로 각자의 인덱스를 사용
- Prefixed Index : 파티션 키와 인덱스 키가 동일하다
- Non Prefixed Index : 파티션 키와 인덱스 키가 다르다
SQL 최적화의 원리
- Optimizer
- SQL의 실행 계획을 수립하고 SQL을 실행하는 DBMS의 소프트웨어
- Data Dictionary에 있는 오브젝트 통계, 시스템 통계 등의 정보를 사용해서 비용을 산정
- 실행계획을 PLAN_TABLE에 저장 → 조회해서 실행 계획 확인 가능
- 옵티마이저 실행 방법
- Parsing 해서 SQL 문법 검사 및 구문 분석 수행
- 구문 분석이 완료되면 Rule Based 혹은 Cost Based로 실행 계획 수립
- 기본적으로 Cost Based 사용
- 실행 계획 수립 완료 후 SQL 실행 → fetch data
- 옵티마이저 엔진
- Query Transformer : 효율적인 실행을 위해 SQL을 변환
- Estimator : 통계정보를 사용해서 SQL 실행비용 계산
- Plan Generator : SQL을 실행할 실행 계획 수립
인덱스
- 인덱스는 데이터를 빠르게 검색할 수 있는 방법 제공
- 인덱스는 여러 개의 칼럼으로 구성될 수 있다.
- PK는 자동으로 인덱스가 만들어진다
- 인덱스의 구조
- Root Block : 인덱스 트리에서 가장 상위에 있는 노드
- Branch Block : 다음 단계의 주소를 가지고 있는 Pointer로 되어 있다.
- Leaf Block
- 인덱스 키와 ROWID로 구성되고 인덱스 키는 정렬되어 저장되어 있다.
- Double Linked List 형태로 되어 있어 양방향 탐색 가능
- 인덱스 생성
CREATE INDEX IND_EMP ON EMP (ENAME ASC, SAL DESC);- 인덱스 스캔
- 인덱스 유일 스캔(Index Unique Scan)
- 인덱스 키 값이 중복되지 않는 경우
- 인덱스 범위 스캔(Index Range Scan)
- SELECT문에서 특정 범위를 조회하는 WHERE문을 사용할 경우 발생
- LIKE, BETWEEN이 그 예
- 인덱스 전체 스캔(Index Full Scan)
- 검색되는 인덱스 키가 많은 경우 Leaf Block 전체 읽어 들임
- High Watermark : 테이블에 데이터가 저장된 블록에서 최상위 위치를 의미 → 이것 이하까지만 Table Full Scan을 함
- 인덱스 유일 스캔(Index Unique Scan)
옵티마이저 조인
Nested Loop 조인
하나의 테이블에서 데이터를 먼저 찾고 그 다음 테이블을 조인 하는 방식
먼저 조회되는 테이블을 외부 테이블(Outer Table), 나중 테이블을 내부 테이블(Inner Table)
RANDOM ACCESS 발생 → 많으면 많을수록 성능 지연
orered 힌트는 FROM절에 나오는 테이블 순서대로 조인을 하게 하는 것
- use_nl, use_merge, use_hash 힌트와 함께 사용
SELECT /*+ ORDERED USE_NL(B) */ * FROM EMP A , DEPT B WHERE A.DEPTNO = B.DEPTNO AND A.DEPTNO = 10 ;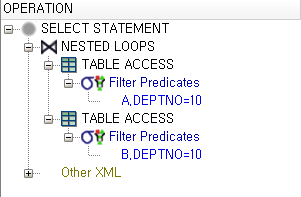
Sort Merge 조인
- 두 개의 테이블에 SORT_AREA라는 메모리 공간에 모두 Loading하고 SORT 수행
Hash 조인
- Hash 메모리에 로딩하고 해시 테이블 생성
- CPU 연산을 많이 한다
'OLD' 카테고리의 다른 글
| 2. 데이터와 2진법(부동소수점에 대하여) (2) | 2023.11.24 |
|---|---|
| 1. 운영체제를 알아야 하는 이유 (0) | 2023.11.17 |
| 1. 컴퓨터 구조를 공부하는 이유 (0) | 2023.11.16 |
| MyBatis의 fluchCache옵션에 대하여 (0) | 2023.04.11 |
| SQLD 정리 1 (0) | 2023.02.09 |