값을 변경하는 작업(UPDATE)을 할 때는 변경하기 전의 값을 바라봐도 상관없는 검색(SELECT)를 제외하고는 아무도 그 값에 접근할 수 없도록 해야 한다.
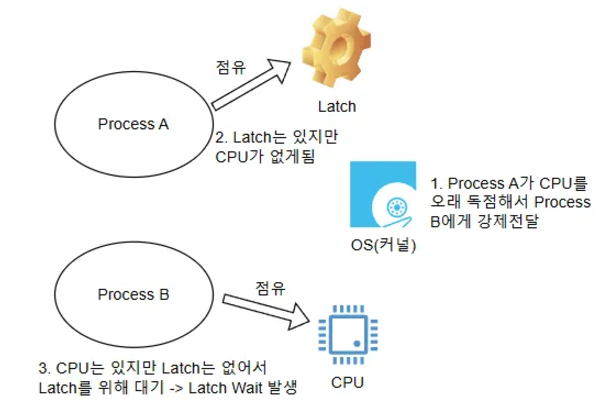
→ UPDATE 문은 이러한 이유로 자동으로 LOCK을 걸게 된다. 이 경우 **LOCK에 의한 대기(WAIT)**가 발생한다.
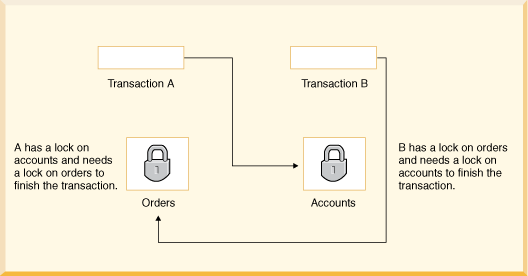
Dead Lock : 서로가 상대가 보유하고 있는 LOCK을 기다리느라 교착 상태 발생
예시)
Transaction A는 트랜잭션을 끝내기 위해 Accounts 를 변경하고 Orders를 변경해야 한다. (Order를 참조하여 회계전표를 생성하고 Order의 상태를 전기 상태로 바꾸기 위해)
Transaction B는 Orders를 작업하고 Accounts를 작업해야 한다.(Accounts에 전기된 오더를 취소하기 위해 Accounts 테이블을 변경해야 할 때)
이 때, 마침 서로가 원하는 다음 데이터가 각각 상대방이 Lock을 걸고 있는 데이터일 때 Dead Lock이 발생하게 된다.
-- TRANSACTION A - ACCOUNTS의 NO = 1 ROW의 LOCK을 보유
UPDATE ACCOUNTS SET COL1 = 2 WHERE NO = 1
UPDATE ORDERS SET COL1 = 2 WHERE NO = 2
-- TRANSACTION B - ORDERS의 NO = 2 ROW의 LOCK을 보유
UPDATE ORDERS SET COL1 = 3 WHERE NO = 2
UPDATE ACCOUNTS SET COL1 = 3 WHERE NO = 1
→ DEAD LOCK이 발생하여 ORA-00060 에러코드 발생 → 오라클에 의해 한 쪽 ROLLBACK 후 처리
- SQL은 처리 방법(절차)를 기술하지 않는다.(이렇게 저렇게 해라라는 방법에 대한 기술이 없다)
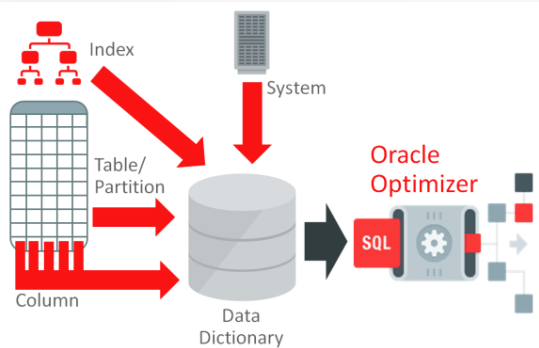
- 대신 옵티마이저(파서)라고 불리는 기능이 실행 계획(plan)이라는 처리 방법을 생성한다. 이 작업은 서버 프로세스의 SQL문 분석에 해당하는 작업이다.
- 실행 계획은 규칙 기반(rule base)과 비용 기반(cost base)라는 알고리즘을 가지고 생성한다. 하지만 규칙 기반은 더 이상 쓰이지 않아 비용 기반만 고려한다.
- 비용 기반이란 '처리 시간이나 I/O 횟수가 가장 적을 것으로 예상되는 처리 방법이 최상'이라는 알고리즘이다.
- 이 비용을 계산하기 위해서 여러 통계 정보를 사용한다.
옵티마이저 동작 원리
- 비용 계산을 위해 데이터 딕셔너리 뷰의 USER_TAB_STATISTICS와 같은 통계 정보를 이용한다.
비용 계산에 필요한 정보들
실행 계획 수립의 한계와 공유 풀(Shared Pool)
어떤 처리 방법이 가장 좋은지(비용이 적은지)를 판단하기 위해서는 모든 처리 방법의 비용을 비교해야 한다. 모든 처리 방법을 비교한다는 것은 수 많은 경우의 수에 대한 예상치를 계산해야하기 때문에 그 자체로 비용(자원)이 많이 든다. 즉, 분석에 드는 CPU 자원이 아까워지는 현상이 발생할 것이다. 그럼 이 실행 계획을 공유해서 자원 소비를 줄이는 방법을 자연스럽게 생각하게 된다. Ch3에서 이미 캐시와 공유 메모리에 대해 알아보았다. 이 실행계획도 서버 프로세스들이 서로 공유한다면 실행 계획을 수립하는 데 사용되는 자원을 줄일 수 있다. (*또한, 선정된 실행 계획이 무조건 가장 좋은 계획이 아닐 수 있다. 어디까지나 예상이기 때문이다. SQL 튜닝(인덱스 등을 활용한)을 통해 더 나은 실행 계획을 세우도록 유도할 수 있다.)
공유 풀(Shared Pool)이라는 공간이 공유 메모리 영역(SGA)에 존재한다. 공유 메모리는 대부분 버퍼 캐시로 사용되고 남은 일부가 공유 풀로 사용되어 그 안에 통계 정보나 실행 계획 등의 캐시 데이터가 저장된다.
실행 계획 등은 라이브러리 캐시(Libary Cache) 공간에 캐싱된다.
공유 풀의 구조
같은 SQL은 같은 실행 계획을 사용한다. 그러면 오라클은 어떻게 같은 SQL을 판단할까?
바인드 변수의 사용
SELECT ID, CUST_NAME, TEL_NO
FROM CUST_INFO
WHERE ID = '001'
SELECT ID, CUST_NAME, TEL_NO
FROM CUST_INFO
WHERE ID = '002'
-- 위 두 가지 SQL은 오라클이 다른 SQL로 취급한다. 오라클은 SQL문을 하나의 문자열로 간주하기 떄문이다.
SELECT ID, CUST_NAME, TEL_NO
FROM CUST_INFO
WHERE ID = :P1
SELECT ID, CUST_NAME, TEL_NO
FROM CUST_INFO
WHERE ID = :P1
-- 바인드 변수를 사용하여 SQL을 실행하면 오라클은 'P1'에 어떤 값이 담기든 같은 SQL로 간주한다.
-- 같은 SQL이 실행된 것으로 판단하여 이전에 캐시에 저장해둔 실행 계획을 가져와 SQL을 처리한다.
- Hard Parse : 공유 풀에 실행 계획이 없어 실행 계획을 새로 생성. 위 경우에 해당한다. 사용자(Client)는 같은 SQL이라고 생각해도 오라클은 그렇게 판단하지 않는다.
- Soft Parse : 공유 풀에 있는 실행 계획을 재사용. 아래 경우에 해당한다.
이처럼 공유 풀과 바인드 변수를 사용하여 소프트 파스를 유도하여 실행 계획 수립에 대한 비용을 낮추는 방법이 사용된다.
공유 풀 정보 with statspack report
- Statspack은 오라클의 분석용 도구이다.
예시 정보실제 예시
- 위 통계를 보고 parse를 위한 CPU사용량 등이 적절한 지에 대한 판단을 할 수 있을 것
정리
- SQL문은 처리 방법에 대한 기술이 없어 분석(parse)을 통해 처리 방법(실행 계획)을 수립한다.
- 실행 계획에도 좋고 나쁨이 있다.
- 실행 계획을 생성하는 데 사용되는 비용을 줄이기 위해 공유 풀(라이브러리 캐시)에 실행 계획을 캐시해서 재활용.
Cache Memory is a special very high-speed memory. The cache is a smaller and faster memory that stores copies of the data from frequently used main memory locations. There are various different independent caches in a CPU, which store instructions and data. The most important use of cache memory is that it is used to reduce the average time to access data from the main memory.
- 캐시는 캐시 메모리라고 불리며 빠른 속도의 메모리이다. 캐시 메모리는 메인 메모리에서 자주 사용되는 데이터를 더 빠르게 접근하기 위해 따로 저장해두는 메모리를 뜻한다.
CPU와 메모리 사이에 위치한 캐시 메모리
- 위는 컴퓨터 구조에서의 캐시 개념을 설명한 것이다. 일반적으로 캐시는 '자주 쓰이는 데이터를 더 빠르게 접근하도록 임시보관하는 메모리 공간'이라고 생각하면 된다.
- 오라클 시스템에서의 캐시를 살펴보기 이전에 일반적인 캐시 개념을 이용해 유추해보자면 시간이 상당히 걸리는 디스크 접근 횟수를 줄이기 위해 자주 쓰이는 데이터를 캐시라는 메모리 공간에 두고 사용하지 않을까라는 추측을 할 수 있다.
오라클의 캐시(데이터 캐시 혹은 버퍼 캐시)
- 오라클의 캐시는 data cache 혹은 buffer cache라고 불린다. 서버 프로세스(클라이언트의 요청을 처리하는 오라클 프로세스)가 원하는 데이터가 캐시에 존재하면 그 데이터에 접근하여 DISK I/O를 줄인다. 즉, SQL의 처리 속도를 높인다.
오라클 캐시의 데이터 관리 단위 : 블록
- 오라클은 'block'이라는 단위로 데이터를 관리한다. 디스크 I/O 및 버퍼 캐시 모두 블록 단위로 관리한다.(OS에도 블록이라는 개념이 있지만 이것과는 다르다)
- 데이터를 한 개만 꺼내오려고 해도 필요한 데이터를 포함한 블록 자체가 캐시에 보관된다. 2KB, 4KB, 8KB, 16KB, 32KB 등 블록 사이즈를 고를 수 있다.
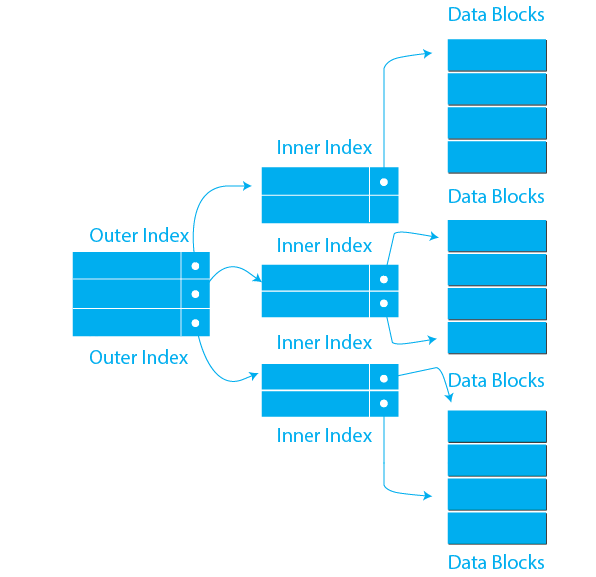
Multi Level Index 구조
- 그림과 같이 인덱스가 단계적으로 되어 있을 때 인덱스를 이용해 데이터를 구하기 위해서는 Outer인덱스의 블록에서 데이터를 가져와(DISK IO 1회) Inner 인덱스 블록을 찾으러 다시 디스크에 접근한다(DISK IO 2회). 그리고 나서 데이터의 주소를 가져와 데이터 블록에 다녀온다.(DISK IO 3회). 위와 같은 구조에서는 디스크에 총 3번을 접근해야 원하는 데이터에 접근할 수 있다.
- 이 때, 원하는 데이터가 데이터 캐시(버퍼 캐시)에 존재한다면, DISK에 접근을 한 번도 하지 않고 디스크 접근이라는 물리적인 움직임 없이 전기적인 신호만으로 클라이언트의 요청에 대한 응답이 가능하다. 이것이 캐시를 이용하는 이유이다.
공유 메모리(SGA;System Global Area)
- 프로세스는 캐시를 공유한다. 기본적으로 다른 프로세스의 메모리를 보는 것을 불가능하다. 데이터에 손상을 입히지 않도록 OS가 제한을 두기 때문이다. DBMS는 이런 불편한 점을 해결하고 다른 프로세스와 데이터를 공유하기 위해 OS의 기능 중 특수한 메모리 기능인 '공유 메모리'를 사용한다. 즉 자신의 캐시를 다른 프로세스도 볼 수 있게 되고 자신 또한 다른 프로세스의 캐시를 볼 수 있게 된다. 이런 공유 메모리 영역을 오라클에서 SGA(System Global Area)라고 불린다. 공유되지 않는 메모리는 PGA(Program Global Area, 이 명칭은 Process가 Program이 실행된 형태를 의미하는 것을 안다면 쉽게 와닿는다)
- 메모리의 데이터를 공유하기 떄문에 데이터에 손상을 가하지 않도록 락을 걸어 배타 제어(exclusive control)을 DBMS가 내부적으로 수행한다. 예를 들어, 동시에 같은 데이터를 변경하려고 하는 등의 시도를 발생하지 않도록 방지하는 것이다.
오라클 시스템 구조책 참고 이미지
버퍼 캐시를 정리하는 LRU 알고리즘
- 정보처리기사에서 페이징 처리 알고리즘에서 배웠던 LRU 알고리즘이 버퍼 캐시를 정리하기 위해 쓰인다. 간단하게 최근에 사용하지 않은 데이터부터 캐시 아웃(버리기)하는 것이다.
데이터 변경도 캐시에서 이루어진다
- 데이터를 변경(update)하는 것과 같은 요청 또한 캐시에서 선제적으로 이루어진다. 설명하자면 클라이언트의 데이터 변경(UPDATE)요청 시 서버 프로세스는 디스크에 직접 변경된 데이터를 전달하여 기록하지 않고 버퍼 캐시에 읽어온 데이터를 변경하여 놔둔다. 이러면 디스크 IO없이 UPDATE SQL요청을 빠르게 처리하고 클라이언트에게 작업완료 응답을 보낼 수 있다.
- 서버 프로세스가 캐시에 변경된 데이터를 두면 백그라운드 프로세스인 DBWR가 캐시에서 변경된 데이터가 버려지기 전에 디스크에 기록한다. 디스크에 부하를 주지 않기위해 정기적으로 수행한다.
모든 것을 버퍼 캐시에 두지는 않는다
- 오라클은 큰 테이블이라고 판단하면 풀 스캔한 것을 버퍼 캐시에 오랜 시간 보관하지 않도록 하고 있다. 일반적으로 풀 스캔 시의 데이터는 버퍼 캐시에 적재되지 않는다고 생각하면 된다.
- 큰 테이블, 작은 테이블 등의 기준은 '_small_table_threshold' 과 같은 설정값을 바꾸어 조정할 수 있다.
스토리지 캐시와 OS의 가상메모리
스토리지라는 저장장치의 캐시를 이용하면 IO 시간을 줄일 수 있다
스토리지 캐시 사용 시 구조
- 스토리지의 캐시에만 데이터 CRUD를 하면 OS입장에서는 스토리지가 캐시 데이터를 알아서 디스크에 기록할 테니 작업이 끝난 것으로 간주할 수 있다. 즉, DBMS입장에서도 디스크 IO가 실제로 이루어지지 않고 스토리지의 캐시에만 기록을 적재한 것이지만 디스크 IO가 끝난 것으로 간주하여 응답을 빠르게 할 수 있다.
- 이렇듯 서버 프로세스가 버퍼 캐시를 사용하는 것만이 데이터 처리의 효율성을 증가시키는 것이 아니라 스토리지 레벨에서도 효율성을 증가시키는 방법이 있다는 것을 알 수 있다.
가상 메모리 때문에 버퍼 캐시가 항상 속도를 증가시키는 것이라고 단언할 수 없다.
- 가상 메모리란 메모리에서 사용 빈도가 낮은 데이터를 물리적인 디스크에 보관하고 메모리에 있는 것처럼 간주하는 기술이다. 이는 OS 레벨에서의 기능이기 때문에 DBMS는 이를 고려하지 않을 것이다.
- 그렇다면 버퍼 캐시가 사용 가능한 물리 메모리의 용량보다 크게 설정되어 있다면 어떻게 될까?
- 그렇게 되면 OS는 가상메모리 기술을 사용해 버퍼 캐시가 사용할 초과분의 용량을 디스크에 마련해 이를 메모리처럼 사용하게 할 것이다.
- 그리고 이 가상 메모리 공간에는 버퍼 캐시에서 잘 사용되지 않는 데이터를 보관하게 하는 것이 가장 효율적일 것이다. 그러다 서버 프로세스가 가상 메모리에 있는 데이터를 요청하면 어떻게 될까?
- 가상 메모리는 디스크에 있기 때문에 디스크 IO가 일어날 것이다. 그러면 서버 프로세스 입장에서는 캐시에만 접근해서 데이터를 가져왔는데도 불구하고 디스크 IO가 일어난 것과 같은 속도로 처리되어 캐시를 사용하는 의미가 없어지게 된다. 즉 아무런 효과도 없는 현상이 발생한다. 가상 메모리 개념과 버퍼 캐시의 개념이 서로 상충하기 때문이다.
- 최근에는 메모리 값이 저렴해지고 용량이 커졌기 때문에 가상 메모리를 사용하지 않는 것을 권고한다. 이렇게 OS레벨에서의 기술과 DBMS레벨에서의 기술이 서로 상충되면 문제를 해결하기 어렵기 때문이 아닐까 싶다
*OS의 버퍼 캐시도 고려해야 한다.
- OS에도 파일 캐시나 페이지 캐시라고 불리는 버퍼 캐시가 있다. 오라클의 버퍼 캐시와 같은 역할을 수행한다. 그렇기 때문에 오라클을 재기동하고 오라클의 버퍼 캐시를 비워도 OS가 재기동되지 않았다면 OS 버퍼 캐시에 데이터가 계속 남아 성능 측정에 오류가 생길 수 있다.(OS의 버퍼 캐시에서 데이터를 가져왔는데 디스크IO한 것이라고 판단할 수가 있다.)
- 프로세스 내에 존재하는 실행 단위. 하나의 프로세스 안에서 처리를 병렬로 하고 싶을 때 사용
일반적인 프로세스와 데이터베이스 프로세스의 차이
- 데이터베이스를 사용하지 않는 프로그래밍에서는 일반적으로 개개의 프로세스가 자신이 가진 변수(데이터)를 처리하는 것이 일반적이지만 데이터베이스의 프로세스는 여러 프로세스나 사용자가 하나의 데이터베이스(데이터 집합)에 접근한 다는 점이 큰 차이점이다. 즉, 여러 사용자나 프로그램이 데이터베이스의 데이터를 공유한다.
오라클이 여러 개의 프로세스로 구성된 이유
위의 그림을 보면 RECO, PMON, SMON, DBW0, LGWR, ARC0 등 오라클 데이터베이스는 여러 개의 프로세스를 지니고 있다. 이와 같이 여러 종류의 프로세스가 있기도 하고, DBW0, DBW1 ... 와 같이 동일한 종류의 프로세스가 여러 개 있기도 하다.
동일 종류의 프로세스가 여러 개인 이유는? - 디스크 I/O 대기시간에 CPU를 쉬게 하는 낭비를 최소화하도록 다른 프로세스가 CPU를 사용하여 다른 일을 해서 CPU를 쉬게 하지 않도록 하기 위함일 것이다. DBWx, ARCx 모두 디스크에 데이터를 I/O하는 작업을 하는 프로세스이다.
서버 프로세스와 백그라운드 프로세스의 역할
오라클은 서버 프로세스와 백그라운드 프로세스로 구성되어 있다.
- 서버 프로세스 : SQL문을 처리하는 프로세스
- 백그라운드 프로세스 : 서버 프로세스를 도와주는 프로세스, 위 그림에서 RECO, PMON, SMON, DBW0, LGWR, ARC0 들이 해당된다.
오라클 시스템 구조
클라이언트(유저 프로세스)는 서버 프로세스와 통신한다. 이 때 클라이언트는 자바, C, SQL*Plus등 데이터베이스 입장에서의 사용자를 의미한다.
각 프로세스가 수행하는 처리
SQL문의 수신 - 서버
SQL문의 파싱 - 서버
데이터 읽기 - 서버
데이터 기록 - 백그라운드(DBWR)
SQL문의 결과 회신 - 서버
로그 기록 - 백그라운드(LGWR)
각종 정리 - 백그라운드(PMON)
로그 보관 -백그라운드(ARC0)
서버 프로세스 : 1, 2, 3, 5 역할 수행(수신-파싱-읽기-회신)
백그라운드 프로세스 : 4, 6, 7, 8 역할 수행
- 예를 들어 '4. 데이터 기록'은 서버 프로세스가 하지 않고 DBWR이 한다. 즉 서버 프로세스는 디스크에서 데이터를 읽어오지만 데이터를 기록은 하지 않는다.
- 서버 프로세스가 모든 일을 다 하게 되면 회신이 늦어지는 단점이 생겨 이를 백그라운드 프로세스에게 넘기고 클라이언트 응대에 집중한다.
*참고로 서버 프로세스는 shadow process, foreground process 라고도 불린다. 서버 프로세스라는 용어는 오라클에서만 클라이언트의 요청에 대응하여 SQL을 처리하는 프로세스를 가리키기 위해 쓰이는 용어에 가깝다.