인덱스를 사용할 때는 인덱스 컬럼을 가공하지 않아야 인덱스를 정상적으로 사용할 수 있다.
- 정상적으로 사용한다는 것은 인덱스의 리프 블록에서 스캔 시작 지점을 찾아 거기서부터 스캔하다가 중간에 멈추는 것(Range Scan)을 의미한다.
- 인덱스를 full scan 하는 것은 인덱스를 제대로 사용하는 것이 아니다. 인덱스 컬럼을 가공하게 되면 full scan 방식으로 인덱스를 사용하기 때문에 좋지 않다.

- 인덱스 컬럼을 가공하지 않았을 대는 INDEX RANGE SCAN을 사용한다.
- 인덱스 컬럼 가공 시 인덱스를 사용하지 못하고 TABLE FULL SCAN 한다.
OR Expansion - 옵티마이저의 실행계획 선택 예시
- or 조건을 union all 조건으로 바꾸는 방법
- USE_CONCAT HINT 를 사용하면 OR 조건을 UNION ALL 로 확장하게 된다.(보통의 경우에는 UNION ALL로 확장하는 게 더 비용적으로 나을 때 채택된다.
- 옵티마이저가 알아서 했을 때 CONCAT이 작동하지 않았다. 아마 CONCAT을 사용했을 때 COST가 더 높기 때문일 것이다. 5행과 6행에서 ACCESS가 각각 동작하고 이를 OR 로 엮었다. 그 이후 BATCH I/O를 한 번 실행함.
- ACCESS predicates for an index are used to fetch the relevant blocks by applying search criteria to the appropriate columns. (조회 조건을 적용하여 리프 블록을 검색하는 동작)
- FILTER predicates are evaluated after the blocks have been fetched. (검색된 블럭들을 조회 조건으로 필터링하는 동작)
- table access by local index rowid batched : 인덱스 리프블록을 버퍼 캐시에서 찾지 못했을 때 바로 디스크 I/O 하지 않고 일정량 모아서 BATCH로 디스크 I/O 하는 방식.
- USE_CONCAT을 사용하여 강제로 UNION ALL을 적용한 모습. 총 COST가 1804로 힌트가 없는 SQL의 COST인 1794 보다 크다. 그러므로 채택되지 않은 실행계획 중 하나이다.
- OR 조건이 없어지고 table access by local index rowid batched 가 2번 실행되었다.
- INDEX BATCH IO가 두번 실행되는 건 UNION ALL을 사이에 두고 SQL이 나누어졌기 때문인 듯함.
- 5과 7행 9행 ACCESS, FILTER, ACCESS가 동작
- 7행에서 LNNVL 함수는 내부 조건이 FALSE 거나 NULL이면 TRUE 를 반환한다.
- PROD_ID = 20이면서 CUST_ID = '5163'가 아닌 것과 NULL인 것, 즉, PROD_ID AND (CUST_ID IS NULL OR CUST_ID != 5163) 을 찾았다.
- 이와 같이 변환된 것이다.
- 첫 번째 SQL은
1. 인덱스 검색
2. 인덱스 검색
3. OR 연산
4. Table Access
- 두 번째 SQL은
1. 인덱스 검색
2. Table Access
3. 인덱스 검색
4. Table Access
5. Concatenation 연산
- IN 은 OR의 다른 표현일 뿐이므로 OR과 마찬가지로 생각하면 된다.
- 결론은 옵티마이저는 OR과 IN 조건의 경우 쿼리변환을 통해 index range scan으로 처리하기도 한다는 것이다.
결합인덱스는 Range Scan을 위해서 인덱스 선두 컬럼이 가공되지 않은 상태로 조건절에 있어야 한다.
- (PROD_ID, CUST_ID) 가 인덱스로 구성되어 있다면 PROD_ID가 가공되지 않은 상태로 조건절에 있어야 INDEX RANGE SCAN이 가능하다.
- 선두 컬럼이 가공되지 않은 상태로 있다고 무조건 효율적인 인덱스 사용이 이루어지는 것은 아니다.
결합 인덱스는 SORT(정렬)이 생략될 수 있다.
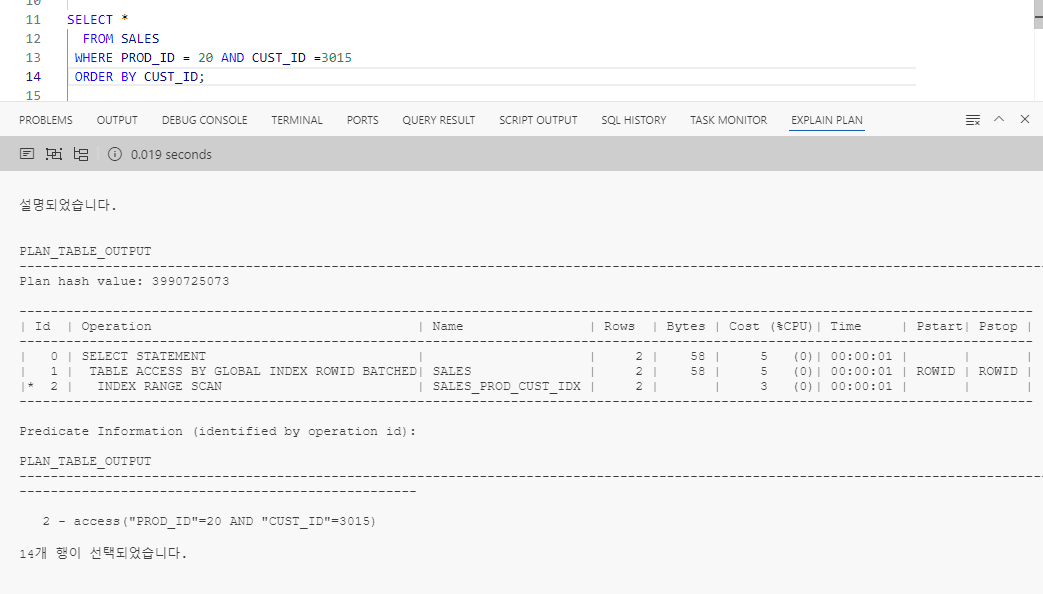
- PROD_ID 와 CUST_ID의 결합인덱스를 사용한 검색 후 ORDER BY에 CUST_ID를 넣으면 SORT 연산이 실행되지 않는다. 이미 인덱스를 검색하는 과정에서 같은 값의 PROD_ID 내에서는 CUST_ID가 ASCENDING 으로 정렬되어 있기 때문이다.
- 마찬가지로 MAX와 MIN 같이 양 끝단에 있는 값을 찾을 때 이미 CUST_ID가 정렬되어 있기 때문에 왼쪽 끝 혹은 오른쪽 끝의 값 하나만 읽으면 되어서 ROWS를 보면 레코드 1개만 찾은 것을 볼 수 있다.
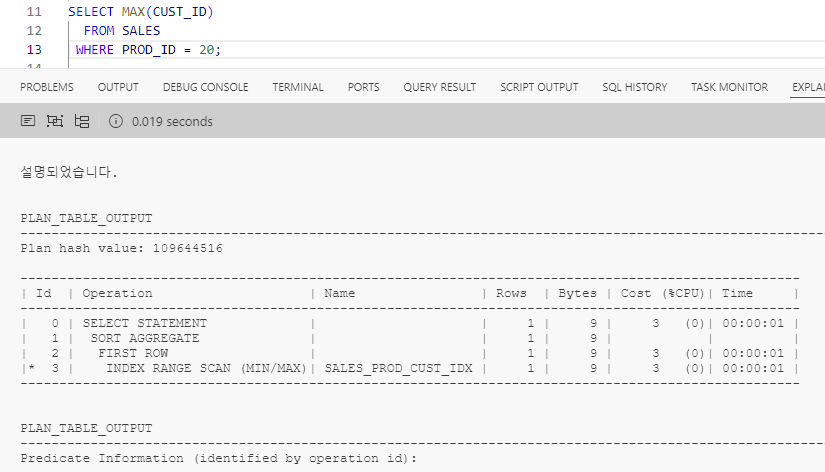
- 하지만 아래와 같이 숫자인 CUST_ID를 문자로 바꾸어 최대 최소를 구하면 문자 형식으로 정렬을 해야 값을 구할 수 있어 모든 레코드를 다 읽게 된다.
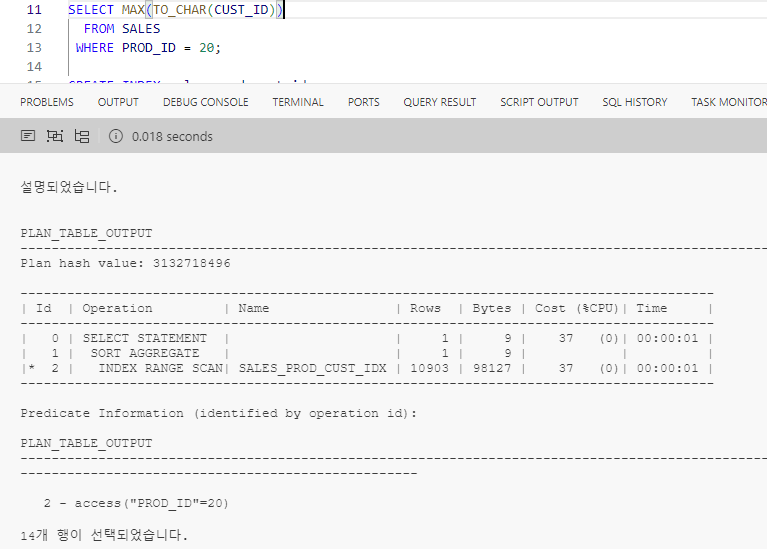
자동 형변환의 위험성

- 두 SQL의 결과가 다르다. 의도한 결과는 2번째 SQL일 것이다. 하지만 DECODE 절에서 NULL과 AMOUNT_SOLD 를 비교할 대 NULL에 맞춰 AMOUNT_SOLD를 CHAR로 바꾼 후 MAX 함수를 사용했기 때문에 999.99가 출력되었다.
- 이 때는 NULL에 TO_NUMBER를 씌워 자동 형변환을 방지하는 방법이 있다(물론 이 SQL에서는 NULL이 아니라 0을 넣으면 형변환이 일어나지 않아 의도대로 출력된다).
옵티마이저가 알아서 하는 역할을 미리 알고 있어야 SQL 튜닝을 더 잘할 수 있다는 교훈을 얻었다.
'OLD' 카테고리의 다른 글
| 개인 프로젝트 - 노트북 VMware 포트포워딩 (0) | 2024.11.25 |
|---|---|
| SAP IMG setting SD(계속 업데이트) (2) | 2024.11.18 |
| 개인 블로그 프로젝트 - 1. 어떤 기능을 만들까? (8) | 2024.10.09 |
| SQLP 기초 - 3. 인덱스 구조 및 탐색 (1) | 2024.10.09 |
| SQLP 기초 - 2. 데이터 저장 구조 및 I/O 매커니즘 (1) | 2024.10.08 |