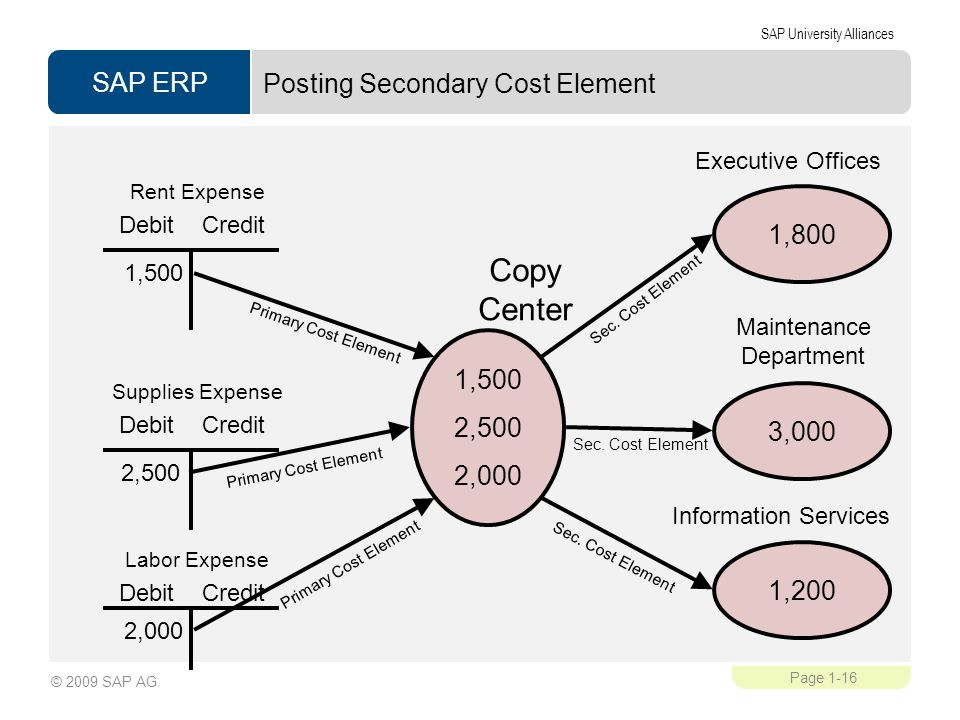
000050000300000001.판매오더 - 출하문서 - 자재문서, 대금청구문서 - 재무회계문서, 관리회계문서
위 프로세스에서 마주치는 용어들 정리글
영어(한글)
- 설명
Sales Order(판매오더) - Header
sales document(영업문서)
- 영업 부서의 비즈니스 트랜잭션 문서들을 뜻함. 고객이 요구한 재화(Goods)나 서비스(Services)에 관련된 데이터를 다룸
- Inquiry(문의), Quotation(견적), Sales Order(판매오더), Outline agreement(계약과 스케줄링), Complaints(반품, 차변 메모, 대변 메모 등)의 종류가 있다.
Net Value(정가)
- 품목(item)들 가격의 총합으로 할인이나 추가금을 고려한 금액으로 SD Document Currency로 표시된다.
SD Document Currency
- 해당 SD문서에 적용되는 통화로 시스템이 Sold-To-Party(판매처)의 customer master record에 있는 정보를 기초로 자동설정한다.
Sold-to-party(판매처)
- 재화나 서비스를 주문한 고객. 계약에 책임이 있는 고객
Ship-to-party(납품처)
- 재화를 받는 고객. 판매처와 다를 수 있음
PO Number
- Inquiry나 Purchase Order 문서 번호를 적어서 판매오더와 연결한다.
- PO번호를 적으면 고객에게 보내는 Delivery Note(출하문서)에 해당 정보를 포함할 수 있다.
Requested delivery date of the document(납품요청일)
- 고객이 재화를 인수할 날짜. 포맷 지정가능(date, day, week, month 등)
- 고객이 요청한 날짜일수도 있고 현재 날짜일 수도 있다. 자동으로 시스템이 한다. 자동으로 설정되는 날짜는 판매오더의 헤더 정보를 컨트롤하는 테이블을 이용해 설정할 수 있다.
- 헤더에 있는 납품요청일을 수정해도 이미 스케줄링 처리가 된 아이템들의 delivery date에 영향을 주지 않는다. 새 납품요청일로 아이템의 일정을 바꾸고 싶다면 Edit -> Fast Change -> Delivery Date 메뉴를 이용한다.
- 납품요청일을 week나 month 형식으로 지정하면, 시스템이 자동으로 공장 달력(factory calender)를 확인하여 첫 번째로 유효한 working day를 납품요청일로 지정할 것이다.
sales documentComplete delivery defined for each sales order?(일괄납품)
- 이 판매 오더가 한 번의 납품(delivery)으로 처리되어야 하는 지 부분적으로 나눠서 납품되거나 다른 납품에 포함되어서 처리될 수 있는지 설정한다.
Deliverying plant(납품 플랜트)
- 재화가 빠져나갈 플랜트. 이 항목을 입력하면 품목 데이터에 default value가 없다면 자동으로 해당 플랜트가 입력된다.
- 기본적으로 품목의 납품 플랜트는 GR의 customer master record나 material master record에서 가져온다.
Total weight(총 중량)
- 시스템이 자동으로 아이템의 gross weight를 합쳐서 입력한다.
Volume
- 아이템들의 볼륨 총합
Delivery block(납품 보류)
- 이 판매오더 전체가 납품 보류상태로 된다.
- Sales Document 유형에 따라 이 값을 제안한다.
- 헤더가 아닌 아이템별로 설정할 수도 있다.
- TVLSP 테이블에서 문서 유형별로 설정가능한 보류 상태 값이 등록되어 있다. 다만 스케줄 라인 레벨에서는 항상 납품 보류가 가능하다.
- 특정 문서 유형에 납품 보류를 기본값으로 설정하는 상황의 예시에는 무상판매와 같은 경우 출하가 일어나기 전에 담당자나 책임자가 확인한 후 납품 보류를 해제하는 프로세스가 필요할 때 사용할 수 있다.
- 신용 체크 기능(credit limit check)을 사용하고 있다면, 시스템이 자동으로 납품 보류를 설정할 수 있다. 수기로 바꿀 수 있지만 다른 SD문서의 값을 바꾼다면 시스템이 다시 신용체크기능을 다시 적용해 납품 보류 설정으로 바꿀 수 있으니 주의할 것.
Billing Block(대금청구보류)
- 판매 문서 유형에 따라 대금청구 보류를 설정할 수 있다.
- 아이템 레벨에서도 아이템 별로 설정가능하다.
- 대금청구문서가 생기기전에 가격을 한 번 더 확인하도록 할 때 이 기능을 사용할 수 있을 것이다.
Pricing Date(가격결정일)
- 가격과 환율 같은 일자 기반 가격 결정 요소를 결정하기 위한 일자.
- 대금청구문서를 집합적으로(collectively) 처리할 때 선택 기준이 되는 일자들 중 하나이다.
- 시스템은 기본적으로 현재날짜를 제안하며 수기로 수정할 수 있다.
- 과거일자로 적는다면 경고 메시지가 뜬다.
- 커스터마이징을 통해 default value를 설정할 수 있다. 예를 들면 납품요청일을 가격결정일로 자동 지정하는 것이 있다.
- 대금 청구 문서에서는 시스템이 판매오더의 가격결정일을 대금청구일자로 제안한다.
Payment card(지급 카드), Expriation date(만료일), Card Verification Value(카드 검증 코드)
- 카드와 카드의 만료일, CVV 코드
Payment terms(지급 조건)
- 현금 할인 퍼센트나 지급 기간 등에 관한 결제 조건.
- invoice due date나 discount rate 등에 대한 지급 조건을 정한다.
- 대금청구문서 자동 생성 시 이 조건에 따라 할인을 하거나 추가금을 요구할 수 있을 것이다.
Incoterms(인도 조건) - part1, part2
- part1은 International Chamber of Commerce(ICC)에 의해 정립된 기준에 일치하는 주로 사용되는 거래 조건을 말한다.
- 예를들어 FOB Boston : Free On Board조건으로 Boston에서 출하하는 재화
- part2는 추가적인 정보이다,
- part1이 FOB라면 두번 째 필드는 선적지와 같은 항구 정보를 기입할 수 있다.
Order reason(오더 사유)
- SD문서를 만드는 이유 설정. 매출 관련 통계를 낼 때 기준 중 하나로 사용할 수 있다. 조직의 관점에서 자유롭게 커스터마이징 하면 된다.
- 스탠다드에서는 대변 메모나 차변 메모는 반드시 이 오더 이유를 설정해야 한다.
- 특정 이벤트로부터 생긴 판매오더임을 구분하기 위해 오더 사유를 해당 이벤트 이름으로 만들어 지정하면 추후 해당 이벤트의 효과가 얼만큼 매출을 일으켰는 지 파악하는 통계를 작성할 수 있게 된다.
Sales Area(판매 영역)
- Grouping of sales organization, distribution channel and division.
Sales Organization(판매 조직)
- 특정 재화와 서비스의 판매에 책임이 있는 조직 단위. 법적인 책임이나 고객의 요구나 불만에 대한 책임을 지는 것을 기준으로 나눌 수 있다.
- 유통 채널과 제품군을 영역 조직에 할당한다. 이 3가지의 조합이 판매 영역이다.
Distribution Channel(유통 채널)
- 도매, 소매, 직판 등의 유통 채널을 구분하는 값. 내수, 수출 등을 구분할 수도 있다.
Division(제품군)
- 재화나 서비스를 그룹핑하는 방법 중 하나.
- 자재나 서비스에 대한 Sales area나 Bisiness area를 결정하기 위해 사용된다.
- 제품군을 나눔으로써 각 제품군 담당자들을 위한 관리가능 영역을 설정하는 효과가 생긴다. 예를 들면 식품판매 제품군을 아이스크림과 음료수 매출 관리 담당자가 다르다면 제품군을 통해 각각의 관리 영역을 구분해 줄 수 있을 것이다.
Sales Order(판매오더) - Item - Sales Tab
Order Quantity(오더 수량)
- total 혹은 rounded(반올림) 수량
- 이 아이템에 대한 스케줄 라인이 하나 보다 많으면 총 오더 수량은 스케줄 라인의 rounded quantity 합으로 나타내어 진다.
Denominator(Divisor) for Conversion of Sales Qty into SKU
- 판매 수량을 SKU로 변환하기 위한 분모
- SKU : Stock Keeping Unit, 재고관리 최소 단위를 의미한다.
Numerator (factor) for conversion of sales quantity into SKU
- 판매 수량을 SKU로 변환하기 위한 분자
- 100 bt(분모) <=> 1 ca(분자) 라고 한다면 bt는 sales unit을 의미하고 ca는 같은 양으로 치환한 base unit of measure이다.(자재의 기본 관리 단위), 판매는 bt단위로 하고 다른 재고관리(생산, 구매, 품질검사 등)의 단위는 ca인 경우 사용하는 기능이다.
First Delivery Date
- Delivery Date(납품일)은 고객이 요구한 날이거나 시스템이 자동적으로 가용성 점검과 출하 스케줄링(delivery scheduling)을 통해 제안된 날짜 중 가장 이른 날이 될 수 있다.
- 시스템은 미리 정의된 Delivery activities(picking이나 packing등)의 시간 추정치를 감안하여 Material Availablity Date(사용 가능일), Loading date(적하일), Goods issude date(출고일), transportation planning date(운송계획일) 등을 결정짓는다.
- 자동적으로 위의 날짜들을 계산하게 하려면 영업 문서를 정의하는 IMG 설정에서 Delivery Scheduling과 Transportation scehduling 필드를 활성화 시켜야 한다.
경로 - Tools --> Customizing, Sales and Distribution --> Basic Functions --> Delivery scheduling and transportation scheduling --> Define scheduling by sales document type
- 스케줄 라인이 여러 개면 시스템은 가장 이른 납품일을 보여준다.
Delivery Time(납품시간)
- 계약이나 견적에서 고객과 합의한 납품 시간
Net Value(정가)
- 문서 통화로 표현된 세금을 제외한 아이템의 정가
International Article Number (EAN/UPC)
- 국제물품번호
Customer Engineering Change Status(고객설계변경상태)
- 설계 변경 요청 상태 번호.
- 고객이 요구한 설계 변경 번호를 적는 곳. PP와 관련있음
BOM explosion number(BOM 전개 번호)
- 부품 공급업체가 고객이 물품을 출하하고 수령하는 제품의 생산 시리즈를 식별하는 데 사용하는 번호
Usage Indicator(용도 지시자)
- 자재가 어떻게 쓰이는 지 정의. 견본, 교체, 사은품 등
- 같은 자재가 다른 용도로 같은 고객에게 판매될 때 구분할 수 있는 지시자가 된다.
Business Transaction Type for Foreign Trade(해외무역 거래유형)
- SAP에서 Business Transaction Type for Foreign Trade는 무역에 대한 비즈니스 트랜잭션 유형.
- 이는 세관 절차를 식별하는 표준 코드로, 이를 통해 발송/수출 트랜잭션의 해외 무역 통계를 보고합니다
Reason for rejection of quotations and sales orders(견적 및 판매 오더의 거부 사유)
- SD문서의 거부사유를 설정함으로써 후속문서 생성을 막는다.
- Inquiry나 Quotation : 다른 문서의 참조로 쓰이지 못한다.
- Sales Order : 품목의 출하 X
- Contracts : 더 이이상 계약 생성할 수 없다.
- 이 필드에 값을 입력하면 시스템이 자동적으로 MRP를 취소한다.
Sales Document Item Category(영업 문서 품목 범주)
- 아이템의 타입들을 구분하기 위한 분류. 무상품목이나 텍스트품목(고객에게 전달한 메뉴얼이나 내부적으로 사용할 메모 등)
- 무상품목의 경우 시스템이 가격 결정 절차를 생략하도록 지정할 수 있다.
Pricing Reference Material(가격결정 참조 자재)
- 가격 결정에 참조한 자재 코드
Product Hierarchy(제품 계층 구조)
- 다양한 특징들을 묶어서 자재를 그룹화하기 위한 코드
- R/3 시스템에서는 3레벨의 계층구조를 가질 수 있다.
- 1레벨 - 5자리, 2레벨-5자리, 3레벨-8자리
| Level |
Example |
Description |
| 1 |
00005 |
Electrical goods |
| 2 |
00003 |
Wet appliances |
| 3 |
00000001 |
Washing machine |
- 이 경우 제품계층구조는 000050000300000001가 된다.
Material Group(자재그룹)
- 몇 가지 특징을 공유하는 자재들을 그룹화할 수 있다.
- 분석 범위(scope of analyese)를 제한하는 데 사용할 수 있다.
- 자재를 검색할 때 사용할 수 있다.
Material group hierarchy 1, 2(자재 그룹 계층 구조)
- 자재 그룹의 그룹을 특정하는 키
Division(제품군)
- 재화와 서비스를 그룹핑하는 방식
- sales area와 business area를 결정하는 데 사용된다.
- SD관점에서는 제품군을 통해 영업 조직에서 특정 제품군의 오더와 서비스를 담당하는 사람이 전문적인 관리영역을 가지도록 특화할 수 있다.(제품군 A는 담당자 A`가 맡는다는 식으로)
Material Pricing Group(자재 가격 결정 그룹)
- 같은 조건을 적용하고 싶은 자재들을 그룹화하는 방식
- 자재 가격 결정 그룹에 대해 조건 레코드를 생성하여 사용할 수 있다.
- 자재 가격 결정 그룹만 사용하는 방식, 고객과 자재 가격 결정 그룹을 사용하는 방식, 가격 그룹과 자재 그룹을 이용한 방식 등으로 조건 레코드를 생성할 수 있다.
Customer Group(고객 그룹)
- 도매/소매 등의 기준으로 나눠진 고객 그룹을 식별한다.
- 가격 결정이나 통계 작성 목적으로 사용될 수 있다.
- 기본적으로 고객 마스터 레코드에서 이 값을 가져오지만 수기로 조정할 수 있다.
Price group(가격 그룹)
- 같은 가격 결정 요구사항을 가진 고객들의 그룹
- 고객 그룹과 마찬가지로 SAP를 사용하는 조직의 니즈에 맞춰 설정하여 사용한다.
- 같은 할인률을 적용하고 싶을 때 사용할 수 있다.
- 고객 마스터 레코드에서 이 값을 가져오지만 역시 수기로 조정할 수 있다.
Price list type(가격 리스트)
- 가격 리스트나 다른 조건 타입(추가금이나 할인금 등)을 식별한다.
- 가격 결정이나 통계를 사용하는데 사용할 수 있다. 조직의 니즈에 맞춰서 세팅하면 된다.
- 고객 마스터 레코드에서 이 값을 가져오지만 역시 수기로 조정 가능하다.
Sales district(판매 구역)
- 지리적으로 나누는 판매 구역
- 조건을 다르게 지정하는 데 사용할 수도 있고 통계를 만드는 기준이 될 수도 있다.
- 역시 고객 마스터에 있지만 수정가능하다.
Sales Order(판매오더) - Item - Shipping Tab
unloading point(하적 지점)
- 자재가 하적하는 지점(화물을 내리는 지점)
Receiving point(입고 지점)
- 주소나 unloading point에 가까운 장소. 각 플랜트마다 여러 입고 지점이 지정될 수 있다.
- 또한 입고 지점은 개별 부서에 할당될 수도 있다.
- 출하문서에 출력되도록 할 수 있다.
Department(부서)
- 연락할 사람이 속한 부서
Delivery Priority(납품 우선순위)
- 품목에 지정된 납품 우선순위
- 특정 자재나 고객/자재 조합에 우선순위를 부여할 수 있다. 집합적으로 납품을 처리할 때 우선순위를 통해 기준을 삼을 수 있다.
- 고객 마스터와 고객/자재 정보 레코드에 있다. 둘 다 값이 존재하면 고객.자제 정보 레코드에서 값을 가져오게 되어 있다.
plant(플랜트)
- plant를 특정한다.
storage location(저장 위치)
- 재고가 저장된 저장 위치를 특정한다.
Shipping point(출하 지점)
- 품목을 출하할 물리적인 위치
- plant, shipping condition, loading group 등의 값을 통해 미리 shipping point와 receiving point를 시스템에 지정해놓을 수 있다.
- 출하 처리를 진행하면서 입고 지점과 출하 지점은 출하를 선택하는 데 중요한 기준이 된다.
- 하나의 납품(출하)은 한 출하 지점에서 혹은 한 한 입고 지점에서 이루어진다.
- 출하 지점에 대한 더 상세한 정보를 제공하고 싶다면 loading point를 특정하면 된다.
- user-speicific하게 출하 지점을 정할 수도 있다(유저 파라미터 VST로 설정).
Partial delivery at item level(품목레벨에서의 분할 납품)
- 고객이 분할 납품을 원하는 지 일괄납품을 원하는 지 설정한다.
- 고객이 분할 납품을 허용한다면 다양한 분할 납품 옵션을 사용할 수 있다.
- 고객 마스터 레코드에 이 값을 가지고 있다.
Route(운송 경로)
- 어떤 경로로 고객에게 자재가 납품되는 지 정할 수 있다.
- 운송 경로를 여러 용도로 사용할 수 있다. 실제 지리적 경로를 나타내거나, 출발지점과 도착지점의 연결을 나타내는 용도로 사용하거나 목표 지점을 나타내는 용도 등으로 사용 가능하다.
- 집합적으로 납품 처리를 하거나 운송 계획에 대한 납품들을 선택할 때 기준으로 사용할 수 있다.
Maximum Number of Partial Deliveries Allowed Per Item(최대 분할 납품 횟수)
- 고객 마스터 레코드에 있으며 고객이 허용하는 최대 분할 납품 횟수를 나타낸다.
Material freight group(자재 운임 그룹)
- 자재들을 묶어 운임 코드나 클래스에 할당하는 코드
- 운임을 결정하는데 사용된다.
- 자재 마스터에 있다.
Order combination indicator(오더 조합 지시자)
- 오더들을 조합할 수 있는지 여부를 체크한다.
- 고객 마스터 레코드에서 값을 가져오며 수기로 값을 변경할 수 있다.
Means-of-Transport type(운송수단 유형)
- 재화가 어떻게 운송되는지를 결정하는 키
- 운송 수단을 결정한다.
- 트럭, 팔레트, 컨테이너, 배 등 재화를 두는 곳을 뜻하거나 운송을 하는 수단을 뜻한다.
Shipping Type(출하 유형)
- 트럭, 메일, 철도, 바다 등 운송과 관련한 값
- leg determination(운송 경로 결정)에 따라 경로들이 출하 유형에 할당된다.
- leg determination이라는 물류 모듈에서 중요한 절차와 관련이 있다.
Means of Transport(운송 수단)
- 운송 수단 카테고리의 포장 자재에 해당 하는 자재를 입력한다.
Special processing indicator(특별처리 지시자)
- 운송이나 운송 비용에 대해 특별한 취급이 필요한 경우 선택한다
- 예를 들면, 특급 배송이나 특별 관세 등의 처리가 필요한 경우
Relevant for POD processing(POD 관련)
- proof of delivery (POD) 공급망 및 물류 업무에서 주문 또는 배송이 정확하게 이루어졌는지를 증명하는 문서
- 고객 마스터 레코드에 있다.
Net Weight
- 총 중량
Gross Weight
- 포장 무게를 제외한 중량
Volume
- 부피
overdelivery, underdelivery tolerance limit(초과,미달 납품 한도)
- 납품이 초과 혹은 미달이 얼만큼 나도 허용가능한지 적는 곳.(고객 마스터 레코드에 있음)